变量、常量和作用域
源文档:https://awq7m8b63wy.feishu.cn/docx/VLFjdBzW7oSsgUx8yDQcaVKNn2c
声明变量时,指针、接口、切片、channel、map、函数的零值为 nil。
const 关键字修饰的声明为常量。
变量遮蔽问题的根本原因,就是内层代码块中声明了一个与外层代码块同名且同类型的变量,内层代码块中的同名变量就会替代那个外层变量。
%d:十进制整数
%f:浮点数
%s:字符串
%t:布尔值
%v:通用格式化标识符,根据值的类型进行格式化
%p:指针地址
%b:二进制表示
%o:八进制表示
%×:十六进制表示(小写字母)
%X:十六进制表示(大写字母)
%c:字符
%q:带引号的字符串
%e:科学计数法表示的浮点数(小写字母e)
%E:科学计数法表示的浮点数(大写字母E)
%g:根据实际情况选择%f或%e格式
%G:根据实际情况选择%f或%E格式
一句话摘要
系统梳理 Go 语言中变量、常量的声明语法与类型推导机制,以及基于代码块的作用域模型和变量遮蔽陷阱的识别与规避。
核心知识点
1. 变量
概念
变量 = 一个特定的名字 + 绑定到内存中特定位置的数据块。程序中所有数据都保存在内存,变量是操作内存的具名引用。
声明规则
- Go 是静态语言,变量使用前必须先声明。
- 同一作用域内不能重复声明。
- 声明的变量必须被使用,否则编译不通过。
完整声明语法:var 变量名 类型 = 初始值
var language string = "Go"
var:关键字language:变量名,位于类型之前string:类型"Go":初始值;未赋值则为该类型的零值
零值表
| 类型 | 零值 |
|---|---|
| 所有整型 | 0 |
| 所有浮点型 | 0.0 |
| 布尔型 | false |
| 字符串 | "" |
| 指针、接口、切片、channel、map、函数 | nil |
批量声明(变量块)
var (
total int = 1234
count int8 = 6
str string = "go program"
char rune = 'A'
has bool = false
)
单行多变量声明
var nickname, sex, email string = "Forest", "man", "767425412@qq.com"
变量块中也可以混合多种类型:
var (
nickname, sex, email string = "Forest", "man", "767425412@qq.com"
a, b, c, d, e rune = 'A', 'B', 'C', 'D', 'E'
i int = 234
j float64 = 3.1415926
n bool = false
)
语法糖一:省略类型(类型推导)
编译器根据右侧初值自动推导类型,推导结果为初值对应的默认类型:
| 字面量类型 | 推导结果 |
|---|---|
| 整型值 | int |
| 浮点值 | float64 |
| 复数值 | complex128 |
| 布尔值 | bool |
| 字符值 | rune |
| 字符串 | string |
限制:此方式只能在有初始值的前提下使用,var b 没有初值会导致编译错误。
如果不接受默认类型,可用显式类型转换覆盖:
var num = int8(110) // 110 按规则推导为 int,但显式指定为 int8
结合多变量声明,可声明多个不同类型的变量:
var i, j, m, n = 99, 3.1415926, 'M', "this is a string"
语法糖二:短变量声明(:=)
语法:变量名 := 初始值
language := "Go"
total := 100
str := "this is a string!"
适用范围:局部作用域(函数内部)。从 Go 1.20 开始,也可用于 if、for、switch 语句的初始化部分,但本质仍属于局部作用域。
2. 常量
概念
常量在源码编译期间创建;一旦声明初始化,整个程序生命周期内其值不变。
声明方法
用 const 关键字替换 var,语法与 var 完全对称,支持单行声明、块声明、单行多常量:
const pi float64 = 3.1415926 // 单行常量声明
const (
size int64 = 4096
i, j, s = 13, 14, "bar" // 单行声明多个常量
)
有类型常量 vs 无类型常量
- 有类型常量:两个类型底层相同但不同的有类型常量,不可以直接比较或混合运算,必须通过显式类型转换。
- 无类型常量:并非真的没有类型,它拥有默认类型(由初始值决定)。在需要时会根据上下文隐式转换为相应类型,灵活性更高。
3. 作用域
概念
作用域针对标识符(不仅是变量),是标识符被声明后可被有效使用的源码区域。作用域是编译期概念,在标识符作用域外使用该标识符会触发编译错误。
导出标识符的条件(同时满足)
- 标识符声明在包代码块中,或者是一个字段名/方法名。
- 名字第一个字符是大写的 Unicode 字符。
代码块域作用域
每个大括号 {} 定义一个代码块,标识符的作用域就是其声明所在的最内层包含代码块。
示例:
func (t T) M1(x int) (err error) {
m := 13 // 代码块1:m、t、x、err 的作用域
{ // 代码块2
type bar struct{} // bar 的作用域始于此
{ // 代码块3
a := 5 // a 的作用域始于此
{ // 代码块4
//... ...
} // a 的作用域终于此
} // bar 的作用域终于此
}
// m、t、x、err 的作用域终于此
}
控制语句中的隐式代码块
if/else if/else 每个子句都有自己的隐式代码块,声明在某个子句初始化部分的变量,其作用域只到该子句结束:
func bar() {
if a := 1; false { // a 的作用域:第一个 if 的隐式代码块
} else if b := 2; false { // b 的作用域:第一个 else if 的隐式代码块
} else if c := 3; false { // c 的作用域:第二个 else if 的隐式代码块
} else {
println(a, b, c) // a、b、c 在此仍可见
}
}
4. 变量遮蔽(Variable Shadowing)
原理
内层代码块中声明了与外层代码块同名且同类型的变量,内层变量会替代外层变量,导致外层变量在内层不可见。
典型 Bug 场景
var a int = 2020
func checkYear() error {
err := errors.New("wrong year")
switch a, err := getYear(); a { // 此处 := 在 switch 初始化块中声明了新的 a
case 2020:
fmt.Println("it is", a, err)
case 2021:
fmt.Println("it is", a)
err = nil
}
fmt.Println("after check, it is", a) // 这里的 a 是外层的 2020,而不是 getYear() 的结果
return err
}
运行输出:
it is 2021
after check, it is 2020
call checkYear error: wrong year
getYear() 返回 2021,但 after check 打印的是 2020,原因就是 switch 初始化语句 := 声明了新的局部 a,遮蔽了包级别的 a。
修复方式:在 switch 外层先用 = 赋值给外层变量,避免在初始化语句中用 := 声明新变量:
year, err2 := getYear()
switch year {
case 2020:
fmt.Println("it is", year, err)
case 2021:
fmt.Println("it is", year)
...
}
5. 相关占位符(fmt 格式化)
| 占位符 | 含义 |
|---|---|
%b | 二进制 |
%o | 八进制 |
%x | 十六进制(小写) |
%X | 十六进制(大写) |
%c | 字符 |
%q | 带引号的字符串 |
%e | 科学计数法(小写 e) |
%E | 科学计数法(大写 E) |
%g | 按实际情况选 %f 或 %e |
%G | 按实际情况选 %f 或 %E |
优缺点与局限性
变量类型推导
- 优点:代码简洁,减少冗余类型声明。
- 限制:只能用于有初始值的声明;推导结果是默认类型(如整数恒为
int,而非int8/int32),需要特定宽度时必须显式转换。
短变量声明(:=)
- 优点:局部变量声明极简。
- 踩坑:在内层作用域中使用
:=容易意外声明新变量而非赋值给外层同名变量,引发变量遮蔽。 - 限制:Go 1.20 之前只能在函数内部使用;包级别变量必须用
var。
常量
- 优点:编译期求值,性能无损耗;防止运行期被修改。
- 限制:常量的值必须在编译期可确定,不能是运行期才能计算的表达式(如函数返回值)。
作用域 / 变量遮蔽
- 核心陷阱:在
if、for、switch初始化语句中用:=,极易遮蔽外层同名变量,且编译器不报错,只在运行时暴露逻辑 Bug。 go vet和 linter(如staticcheck)可检测部分遮蔽场景,但不能覆盖全部。
行动清单
- 动手实验零值:写一个程序,声明整型、浮点、布尔、字符串、切片、map 变量但不赋值,用
fmt.Printf("%v\n", ...)打印默认值,加深记忆。 - 对比三种声明方式:在同一个函数中分别用
var 显式类型、var 省略类型、:=声明同类变量,用%T打印类型,验证类型推导规则。 - 复现变量遮蔽 Bug:把文中
checkYear的问题代码跑起来,观察输出,然后应用修复方案,对比前后差异。 - 阅读
go vet输出:在有变量遮蔽的代码上运行go vet ./...,观察它能捕获哪些情况,记录哪些情况检测不到。 - 练习常量块 + iota:本文未展开
iota,作为延伸:在const块中结合iota定义枚举,验证有类型常量与无类型常量的运算差异。 - 理解作用域图:手绘文中
M1函数的代码块嵌套图(代码块1→2→3→4),标注每个标识符的生存范围,理解编译器的作用域检查逻辑。
数据类型
源文档:https://awq7m8b63wy.feishu.cn/docx/LH3pdLBvpo3A1Xxgml8c0qH4nHh
bit 是二进制的最小单位。
byte 是 uint8 的内置别名,占用 1 个字节(8bit)。
rune 是 int32 的内置别名,占用 4 字节(32bit)。
int、uint 在 32 位系统上占用 4 字节(32bit),在 64 位系统上占用 8 字节(64bit)。
可以使用 unsafe.Sizeof() 函数验证。
数据类型占用空间可参考网站:https://learnku.com/articles/89049
有符号整型(int8 - int64)和无符号整型(uint8 - uint64)的本质差别在于最高二进制位(bit 位)是否被解释为符号位,这点会影响到无符号整型与有符号整型的取值范围。
int、uint、uintptr、byte 等价于 uint8 类型,可以理解为 uint8 类型的别名,用于定义一个字节,所以字节类型也属于整型。
package main
import "fmt"
func main() {
var s int8 = 127
s += 1
fmt.Println(s) // 预期128,实际结果-128
var u uint8 = 1
u -= 2
fmt.Println(u) // 预期-1,实际结果255
}
package main
import "fmt"
func main() {
var a int8 = 59
fmt.Printf("%b\n", a) //输出二进制:111011
fmt.Printf("%d\n", a) //输出十进制:59
fmt.Printf("%o\n", a) //输出八进制:73
fmt.Printf("90\n", a) //输出八进制(带00前缀):0073
fmt.Printf("%x\n", a) //输出十六进制(小写):3b
fmt.Printf("%X\n", a) //输出十六进制(大写):3B
}
package main
import (
"fmt"
"reflect"
"strconv"
)
func main() {
// 整数转浮点数
// 字面量转换方式
var a int = 10
fmt.Printf("%f\n", float64(a)) // 10.000000
// 使用 strconv 包的 ParseFloat 函数转换
var b float64
b, _ = strconv.ParseFloat(strconv.Itoa(a), 64)
fmt.Printf("%f\n", b) // 10.000000
// 使用字符串格式化函数 fmt.Sprintf 将整数格式化为带有小数点的字符串,然后使用 strconv 包中的 ParseFloat 函数将字符串转化为浮点数
formattedString := fmt.Sprintf("%.1f", float64(a))
b, _ = strconv.ParseFloat(formattedString, 64)
fmt.Println("b TypeOf:", reflect.TypeOf(b)) // b Type0f: float64
// 整数转字符串
// str: 10, type of: string
str := strconv.Itoa(a)
fmt.Printf("str: %s, type of: %s\n", str, reflect.TypeOf(str))
str = fmt.Sprintf("%d", a)
// str: 10, type of: string
fmt.Printf("str: %s, type of: %s\n", str, reflect.TypeOf(str))
str = strconv.FormatInt(int64(a), 10)
// str: 10, type of: string
fmt.Printf("str: %s, type of: %s\n", str, reflect.TypeOf(str))
// 复数
var c = complex(5, 6) // 5 + 6i
r := real(c) // 5.000000
i := imag(c) // 6.000000
fmt.Println("c:", c) // c: (5+6i)
fmt.Println("r:", r) // r: 5
fmt.Println("i:", i) // i: 6
// 自定义数值类型,EventInt 与 int32 之间无法相互赋值,需要显式转换
type EventInt1 int32
// 类型别名,二者完全相等,别名 EventInt 会被直接编译为 int32
type EventInt2 = int32
}
一句话摘要
Go 原生提供整型、浮点型、复数三大数值类型,各有确定的内存宽度和取值范围;掌握平台差异、溢出机制、字面值格式、类型转换和自定义类型是正确使用它们的核心。
核心知识点
1. 整型
分类体系
整型分两大类:平台无关整型(宽度固定)和平台相关整型(宽度随 CPU 架构变化)。
- 平台无关整型:有符号
int8 / int16 / int32 / int64,无符号uint8 / uint16 / uint32 / uint64。有符号与无符号的本质差别在于最高 bit 是否被解释为符号位,决定了取值范围。 - 平台相关整型:
int / uint / uintptr。在 32 位系统上int是 32 位(-231 到 231-1),在 64 位系统上是 64 位(-263 到 263-1)。 byte等价于uint8,是uint8的别名,用于表示单字节。
2. 整型的溢出问题
超出类型边界的运算结果会发生静默回绕,不 panic,不报错。
package main
import "fmt"
func main() {
var s int8 = 127
s += 1
fmt.Println(s) // 预期128,实际结果 -128
var u uint8 = 1
u -= 2
fmt.Println(u) // 预期-1,实际结果 255
}
溢出最容易在循环终止条件中被忽略,选择循环变量类型时要格外小心。
Go 1.17 起的检测方式: math 包提供了 math.MaxInt、math.MinInt、math.MaxUint 等常量。对加法可用如下方式检测:
package main
import (
"fmt"
"math"
)
func safeAdd(a, b int) (int, error) {
if a > math.MaxInt-b {
return 0, fmt.Errorf("整数加法溢出: %d + %d", a, b)
}
return a + b, nil
}
3. 整型字面值与格式化
字面值写法(Go 1.13 前):
a := 53 // 十进制
b := 0700 // 八进制,以"0"为前缀
c := 0xaabbcc // 十六进制,以"0x"为前缀
d := 0Xddeeff // 十六进制,以"0X"为前缀
Go 1.13 新增:
a := 0b10000001 // 二进制,以"0b"为前缀
b := 0B10000001 // 二进制,以"0B"为前缀
c := 0o700 // 八进制,以"0o"为前缀
d := 0O700 // 八进制,以"0O"为前缀
Go 1.13 还支持用下划线 _ 作为数字分隔符提升可读性,例如 1_000_000。
格式化输出:
var a int8 = 59
fmt.Printf("%b\n", a) // 二进制: 111011
fmt.Printf("%d\n", a) // 十进制: 59
fmt.Printf("%o\n", a) // 八进制: 73
fmt.Printf("%O\n", a) // 八进制(带0o前缀): 0o73
fmt.Printf("%x\n", a) // 十六进制(小写): 3b
fmt.Printf("%X\n", a) // 十六进制(大写): 3B
4. 整型常用类型转换
整数转浮点数(三种方式):
var a int = 10
fmt.Printf("%f\n", float64(a)) // 字面量转换:10.000000
var b float64
b, _ = strconv.ParseFloat(strconv.Itoa(a), 64) // strconv 转换
formattedString := fmt.Sprintf("%.1f", float64(a))
b, _ = strconv.ParseFloat(formattedString, 64) // fmt + strconv
整数转字符串(三种方式):
var a int = 10
str := strconv.Itoa(a) // str: 10, type: string
str = fmt.Sprintf("%d", a) // str: 10, type: string
str = strconv.FormatInt(int64(a), 10) // str: 10, type: string
整数转布尔(通过关系运算符):
var a int = 10
fmt.Printf("a: %v\n", a > 10) // a: false
fmt.Printf("a: %v\n", a >= 10) // a: true
fmt.Printf("a: %v\n", a == 10) // a: true
fmt.Printf("a: %v\n", a != 10) // a: false
5. 浮点型
Go 提供两种精度的浮点数:float32 和 float64,变量默认值均为 0。
字面值与格式化输出:
var f float64 = 123.45678
fmt.Printf("%f\n", f) // 输出原值: 123.456780
fmt.Printf("%e\n", f) // 十进制科学计数法: 1.234568e+02
fmt.Printf("%x\n", f) // 十六进制科学计数法: 0x1.edd3be22e5de1p+06
6. 浮点数的比较
浮点数遵循 IEEE-754 标准以二进制近似存储,不能直接用 == 比较。float32 有效精度约 7 位十进制数。
var f1 float32 = 16777216.0
var f2 float32 = 16777217.0
fmt.Println(f1 == f2) // true,超出 float32 精度范围导致相等
// 推荐做法:判断差的绝对值是否小于容差 ε
a := 0.1
b := 0.2
c := 0.3
if math.Abs((a+b)-c) < 1e-9 {
fmt.Println("a+b 等于 c")
}
7. 浮点型常用转换
浮点数转字符串:
var a float64 = 10.0
strNum := strconv.FormatFloat(a, 'f', -1, 64)
fmt.Printf("strNum: %s, type of: %s\n", strNum, reflect.TypeOf(strNum))
浮点数转整数(截断,非四舍五入):
var f float64 = 3.14
b := int(f) // 截断小数部分,b = 3
i := int(math.Round(f)) // 使用 math 包四舍五入,i = 3
8. 复数类型
数学上形如 z = a + bi(a 为实部,b 为虚部)的数称为复数。
三种字面值表示方式:
① 字面值初始化:
var c = 5 + 6i
var d = 0o123 + .12345e+5i
fmt.Println("c:", c) // c: 5 + 6i
fmt.Println("d:", d) // d: 83+12345i
直接写的复数常量默认类型是 complex128。
② 使用内置 complex 函数:
c := complex(5, 6) // 5 + 6i
d := complex(0o123, .12345e5) // 83+12345i
③ 使用 real 和 imag 函数获取实部与虚部(返回浮点类型):
var c = complex(5, 6) // 5 + 6i
r := real(c) // 5.000000
i := imag(c) // 6.000000
fmt.Println("r:", r) // r: 5
fmt.Println("i:", i) // i: 6
9. 自定义数值类型
用 type 关键字基于原生数值类型声明新类型:
type MyInt int32
MyInt 与 int32 是不同类型,无法直接互相赋值或混合运算,编译器会报错,必须显式转换:
var a MyInt = 10
var b int32 = int32(a) // 显式转换
10. 类型别名
在类型名和原始类型之间加 =,定义类型别名:
type MyInt = int32
MyInt 与 int32 完全相等,编译后被替换为原始类型,不产生新类型,可以直接互相赋值,无需转换。
自定义类型 vs 类型别名对比:
| 特性 | type MyInt int32 | type MyInt = int32 |
|---|---|---|
| 是否产生新类型 | 是 | 否 |
| 能否直接互相赋值 | 不能,需显示转换 | 能 |
| 编译后处理 | 独立类型 | 替换为原始类型 |
优缺点与局限性
整型溢出:静默回绕是 Go 的设计决策,性能高但调试困难。生产代码中要在循环边界或累加计算处主动检测溢出,勿依赖默认行为。
平台相关整型的坑:int 在 32 位和 64 位系统宽度不同,序列化/反序列化或跨平台数据交换时要使用 int32 / int64 明确宽度,避免隐式截断。
浮点比较:float32 和 float64 均不可用 == 直接判等,金融计算等精度敏感场景应使用 decimal 第三方库,而非原生浮点。
自定义类型的限制:type MyInt int32 会使 MyInt 无法直接使用 int32 的方法集(若有),适合在强类型语义场景使用;若只需别名,用 = 形式。
复数类型的使用场景较窄:complex64 / complex128 主要用于数学/信号处理,日常业务开发极少使用。
行动清单
- 动手验证溢出行为:自己写一个
int8从 127 加到 200 的循环,观察溢出回绕,再用math.MaxInt添加检测逻辑。 - 练习进制字面值:写一段代码分别用十进制、八进制(
0o)、十六进制、二进制定义同一个数,用%b/%o/%x格式化输出验证。 - 浮点比较专项练习:写三组浮点数相等的对比测试(直接
==vs 差值小于1e-9),理解精度丢失的实际影响。 - 区分自定义类型与类型别名:写一个
type Celsius float64和type Kelvin float64的温度转换程序,体会强类型带来的编译期安全保障。 - 了解
strconv包:把Itoa,FormatInt,ParseFloat,FormatFloat四个函数都跑一遍,记住各自的参数含义和使用场景。 - 进阶:学习
math/big包,在遇到超过int64上限的整数运算时使用big.Int,彻底规避溢出。
运算符、流程控制
源文档:https://awq7m8b63wy.feishu.cn/docx/DGQ2d2uXUo6qFpxgQ7gc5w5Fnut
位操作符:
| 操作符 | 描述 |
|---|---|
| & | 按位与,二进制位都为1则为1,否则为0 |
| ^ | 按位异或,二进制位不一样就为1,否则为0 |
| << | 左移,左移n位就是乘以2的n次方 |
| >> | 右移,右移n位就是除以2的n次方 |
switch case 一旦匹配,会直接执行 case 下的操作并退出该分支。
for 循环支持多变量声明(for i, j, k := 0, 1, 2; (i < 20) && (j < 30) && (k < 40); i, j, k = i+1, j+2, k+5)。
for range 循环结构支持遍历数组、切片、字符串、map、channel。
Go 1.22 版本之前需要考虑循环中闭包的问题,1.22 版本之后虽然已更新了“循环变量重用”机制,但仍推荐考虑闭包问题的写法。
参与循环的是 range 表达式的副本,如果需要修改原值,可以使用切片(for i, v := range a[:])或引用(for i, v := range &a)循环。
continue 支持 label,指定跳到多层循环的某一层。
一句话摘要
系统梳理 Go 语言的运算符体系、三种 if/switch 流程控制写法、唯一的 for 循环及其三种形态,并深入剖析 Go 1.22 前后循环变量重用、range 副本、map 随机遍历等经典陷阱。
核心知识点
1. 运算符
算术运算符:+(加)、-(减)、*(乘)、/(除),与多数语言一致。
关系运算符:==、!=、>、>=、<、<=,均返回 bool 值。
逻辑运算符:&&(AND,两边都为 true 才为 true)、||(OR,有一个 true 即为 true)、!(NOT,取反)。
位运算符(操作二进制位):
| 符号 | 含义 |
|---|---|
& | 按位与,二进制位都为 1 则为 1 |
| ` | ` |
^ | 按位异或,二进制位不同则为 1 |
<< | 左移 n 位,等价于乘以 2 的 n 次方 |
>> | 右移 n 位,等价于除以 2 的 n 次方 |
完整示例(two=2,four=4):
package main
import "fmt"
func main() {
two := 2 // 二进制: 0000 0010
four := 4 // 二进制: 0000 0100
result := two & four // 0000 0000 --> 0
fmt.Println(result) // 0
result = two | four // 0000 0110 --> 6
fmt.Println(result) // 6
result = two ^ four // 0000 0110 --> 6
fmt.Println(result) // 6
result = two << four // 将 two 左移 four 位 --> 0010 0000 --> 32
fmt.Println(result) // 32
result = two >> four // 将 two 右移 four 位 --> 0000 0000 --> 0
fmt.Println(result) // 0
}
2. 流程控制 — if 系列
四个关键规则:
if后的布尔表达式不加括号- 可用多个逻辑运算符连接多个条件
- 条件表达式结果必须是
bool类型(true或false) - 左大括号与
if关键字必须同行(gofmt 强制执行)
单分支:
if condition {
}
多分支(两种写法):
// 第一种:两路分支
if boolean_expression {
// 分支1
} else {
// 分支2
}
// 第二种:多路分支
if boolean_expression1 {
// 分支1
} else if boolean_expression2 {
// 分支2
} ... {
} else if boolean_expressionN {
// 分支N
} else {
// 分支N+1
}
3. 流程控制 — switch case
语法结构:
switch initStmt; expr {
case expr1:
// 执行分支1
case expr2:
// 执行分支2
case expr3_1, expr3_2, expr3_3:
// 一个 case 匹配多个值
case expr4:
// 执行分支4
...
default:
// 执行默认分支
}
四个关键特性:
switch后大括号内每个分支以case开头,每个case后是一个或逗号分隔的多个表达式- 每个
switch只能有一个default分支,无论default出现在哪里,都只在所有case不匹配时执行 - Go 先对
switch expr求值,再按case出现顺序从上到下逐一匹配,一旦匹配通常就执行并退出 - Go **取消了每个
case后面的显式 **break,默认不贯穿;如需执行下一个case的逻辑,用fallthrough关键字实现
4. 循环 — for 的三种形态
Go 只有一种循环语句 for,提供三种形式,只有第一种使用分号。
形式一:经典模式(类 C 风格)
for init; condition; post {
}
// init: 控制变量赋初始值
// condition: 循环控制条件
// post: 给控制变量增量或减量
示例——累加 0~9:
var sum int
for i := 0; i < 10; i++ {
sum += i
}
println(sum) // 45
支持多循环变量:
sum := 0
for i, j, k := 0, 1, 2; (i < 20) && (j < 10) && (k < 30); i, j, k = i+1, j+1, k+5 {
sum += (i + j + k)
}
形式二:仅保留条件(类 while 风格)
i := 0
for i < 10 {
println(i)
i++
}
形式三:for…range(遍历复合变量)
可遍历数组、指向数组的指针、切片、字符串、map 及 channel:
for key, value := range 复合变量 {
// ...
}
只需下标时省略 value:
for i := range sl {
// ...
}
只需值时用空标识符替代下标:
for _, value := range sl {
// ...
}
5. 常见陷阱
陷阱一:循环变量重用(Go 1.22 前的大坑)
问题:在 Go 1.22 之前,for range 语句中的循环变量只被声明一次,每次迭代被重用。在循环体内启动 goroutine 并捕获循环变量时,所有 goroutine 实际拿到的是同一个变量的最终值。
var m = []int{1, 2, 3, 4, 5}
for i, v := range m {
go func() {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}()
}
time.Sleep(time.Second * 10)
// 预期: 0 1 / 1 2 / ... / 4 5
// Go 1.22 前实际输出: 4 5 / 4 5 / 4 5 / 4 5 / 4 5
Go 1.22 修复:从 Go 1.22 开始,for 循环(含 for range)的每次迭代都会创建新的循环变量实例,goroutine 中捕获的就是当次迭代的值。
兼容性最佳实践:为在所有 Go 版本保持明确语义,仍推荐用参数绑定的方式:
for i, v := range m {
go func(i, v int) {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}(i, v)
}
陷阱二:参与循环的是 range 表达式的副本
for...range 对数组求值时,会复制一份副本参与迭代,循环期间对原数组的修改不影响已复制的副本。
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
for i, v := range a { // range a: 对数组 a 求值,复制副本
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
// r = [1 2 3 4 5] ← 读的是副本,修改不可见
// a = [1 12 13 4 5] ← 原数组已修改
避免方法:用切片语法 a[:] 传递切片,切片的副本与原底层数组共享数据,能感知到修改:
for i, v := range a[:] { // 传入的是切片副本,指向同一底层数组
...
r[i] = v
}
// r = [1 12 13 4 5] ← 能感知到修改
陷阱三:遍历 map 元素具有随机性
当 map 作为 for...range 的表达式时,副本与原变量指向同一个 map。在循环中新创建的 map 元素可能出现在后续循环中,也可能不出现——顺序不确定。需要确定性顺序时,应先提取 key 排序再遍历。
6. continue 与 break
continue:中断当前迭代,回到 for 条件判断,开始下一次迭代。
var sl = []int{1, 2, 3, 4, 5, 6}
for i := 0; i < len(sl); i++ {
if sl[i]%2 == 0 {
continue // 跳过偶数
}
sum += sl[i]
}
println(sum) // 9 (1+3+5)
带 label 的 continue:用于嵌套循环,跳转到外层循环继续下一次迭代:
loop:
for i := 0; i < len(sl); i++ {
if sl[i]%2 == 0 {
continue loop // 跳到外层循环
}
sum += sl[i]
}
break:彻底跳出整个循环语句。适用于找到目标值后立即停止的场景:
var sl = []int{5, 19, 6, 3, 8, 12}
var firstEven int = -1
for i := 0; i < len(sl); i++ {
if sl[i]%2 == 0 {
firstEven = sl[i]
break
}
}
println(firstEven) // 6
7. 练习代码示例
9×9 乘法表:
import "fmt"
func main() {
for i := 1; i <= 9; i++ {
for j := 1; j <= i; j++ {
fmt.Printf("%d * %d = %d ", j, i, i*j)
}
fmt.Printf("\n")
}
}
字符串遍历(按字节逐个读取):
str := "this is a string"
len := utf8.RuneCountInString(str)
fmt.Println("字符串的长度: ", len)
for i := 0; i < len; i++ {
fmt.Printf("%s\n", string(str[i]))
}
数组/切片遍历:
arr := [5]int{1, 2, 3, 4, 5}
for _, value := range arr {
fmt.Printf("value: %d\n", value)
}
map 多层遍历:
books := map[string]map[string]int{
"四书": {"论语": 80, "大学": 66, "中庸": 60, "孟子": 70},
"五经": {"周易": 90, "诗书": 80, "礼记": 88, "尚书": 78},
"书法": {"兰亭集序": 66, "九成宫碑": 68, "多宝塔": 56},
}
for key, value := range books {
slice := []string{}
for v := range value {
slice = append(slice, v)
}
fmt.Printf("%s: %s\n", key, strings.Join(slice, ", "))
}
优缺点与局限性
switch 的 fallthrough:默认不贯穿是 Go 相较 C/Java 的改进,减少了漏写 break 的 bug;但需要贯穿时必须显式加 fallthrough,初学者容易忘记。
for 循环的统一性:一个 for 覆盖所有循环模式,语法简洁;但不像 Python while/for 分开,语义需通过结构判断。
range 副本机制:对数组遍历时复制副本保证了并发安全,但带来了”修改不可见”的意外;对 map、channel 则不复制底层数据,行为不对称,需特别记忆。
Go 1.22 循环变量行为变更:解决了长期存在的 goroutine 闭包捕获 bug,但修改了语言语义,跨版本项目需注意兼容性。
map 遍历随机性:Go 故意随机化 map 遍历顺序(防止依赖特定顺序),在循环中新增元素是否可见也不确定,不能用 for range map 做依赖顺序的处理。
行动清单
- 动手验证位运算:用
fmt.Printf("%08b", x)打印二进制,直观验证&、|、^、<<、>>的效果。 - 编写 switch 练习:实现一个根据分数段输出等级的程序,练习
case多值匹配和fallthrough用法。 - 复现循环变量重用 Bug:在 Go 1.21 环境(或加
//go:build go1.21指令)复现 goroutine 捕获问题,再用参数绑定方式修复,对比两种方案。 - 验证 range 副本行为:分别用
for range a(数组)和for range a[:](切片)在循环中修改元素,打印结果,理解副本语义差异。 - 完成5个遍历练习:逐一实现文档中的 9×9 乘法表、字符串遍历、数组遍历、切片遍历、map 多层遍历,并在 Go Playground 上运行验证。
- 阅读 Go 1.22 Release Notes:查阅官方说明,确认项目最低 Go 版本,决定是否继续使用参数绑定的兼容写法。
- map 有序遍历实践:实现一个先用
sort.Strings()对 map 的 key 排序,再按序遍历输出的工具函数,解决 map 随机性问题。
函数
函数源文档:https://awq7m8b63wy.feishu.cn/docx/OklJdI9JqocCWGxoz7pcNALtnDg
方法源文档:https://awq7m8b63wy.feishu.cn/docx/SuVBd2VADoBiXqx07jUcsYjnnhb
函数和方法的变长参数:在参数类型前加 … 符号。
go 函数的签名包括:参数列表,返回值列表(参数类型、数量、顺序)。
如果两个函数的签名相同,即使函数名、参数变量名、返回值变量名都不相同,两个函数也是相同类型。
所有类型作为函数参数采用的都是“值传递”的方式,整型、数组、结构体等类型作为实参传递时,拷贝的是自身,但 slice、map 等引用类型的内存对应的是它们的“描述符”,即指向该地址的指针,所以引用类型作为实参传递时,仅拷贝指针而不拷贝内容(浅拷贝),在函数内修改引用类型的内容会导致引用类型外部的内容也被修改。
从 go 1.22 开始,字符串作为参数传递时,传递的也是字符串值的完整拷贝。
函数可以视作一种数据类型(对象)作为参数传递。
package main
import "fmt"
func main() {
// 调用performOperation函数,并将add函数作为参数传递
result := performOperation(add, 10, 5)
fmt.Println("Addition Result:", result) // Addition Result: 15
// 调用performOperation函数,并将subtract函数作为参数传递
result = performOperation(subtract, 10, 5)
fmt.Println("Subtraction Result:", result) // Subtraction Result: 5
}
// 函数作为参数传递的示例
func performOperation(operation func(int, int) int, a, b int) int {
// 调用传递进来的函数并返回结果
return operation(a, b)
}
// 加法函数
func add(a, b int) int {
return a + b
}
// 减法函数
func subtract(a, b int) int {
return a - b
}
一句话摘要
系统梳理 Go 函数从声明、参数传递、返回值,到高阶函数、闭包、defer 的完整机制;核心结论是:Go 函数是一等公民,参数按值传递,defer 以 LIFO 顺序在函数返回前执行,闭包捕获引用环境。
核心知识点
1. 函数声明
基本语法
func 函数名(参数) (返回值) {
// 函数体
}
命名规则
- 由字母、数字、下划线组成,首字符不能是数字。
- 同一包内函数名唯一;首字母大写 → 包外可见,小写 → 包内私有。
函数类型
- 每个函数声明是其函数类型的一个实例。
- 声明函数类型时可省略参数名和返回值变量名:
func(io.Writer, string, ...interface{}) (int, error)
- 两个函数类型的签名相同(参数类型 + 返回类型完全一致),就是相同类型,即便参数名不同:
func (a int, b string) (results []string, err error)
func (c int, d string) (sl []string, err error) // 与上面是同一类型
基础示例
func sum(a, b int) int {
return a + b
}
result := sum(3, 5) // result: 8
2. 参数
形参 vs 实参
- 形参(Parameter):函数签名中定义的变量,函数体内使用形参。
- 实参(Argument):调用时传入的具体值。
值传递语义
- Go 函数参数全部采用值传递(Bitwise Copy)。
- 整型、数组、结构体等类型:拷贝数据本身,函数内修改不影响外部。
- slice、map、channel:内存表示是”描述符”(header),传递的是描述符拷贝,指向同一块底层数据,函数内修改内容会反映到外部。
// 值类型:修改不影响外部
func swap(a, b int) {
temp := a; a = b; b = temp
}
// After swap: x = 10, y = 20(未改变)
// 引用类型:修改影响外部
func updateSlice(sl []string) { sl[0] = "updated" }
// After update: slice = [updated world]
func updateMap(m map[string]string) { m["key"] = "updated" }
// After update: mp = map[key:updated]
⚠️ Go 1.22 起,string 类型作为参数传递行为与整型一致,传递的是字符串值的完整拷贝。
变长参数
- 底层用切片实现,类型前加
...:
func myAppend(sl []int, elems ...int) []int {
fmt.Printf("%T\n", elems) // []int
if len(elems) == 0 { return sl }
sl = append(sl, elems...)
return sl
}
sl := []int{1, 2, 3}
sl = myAppend(sl) // [1 2 3]
sl = myAppend(sl, 4, 5, 6) // [1 2 3 4 5 6]
- 当形参为接口类型或变长参数时,Go 编译器会把实参赋值给接口类型形参或转换为变长形参。
3. 返回值
三种形式
| 形式 | 示例 |
|---|---|
| 无返回值 | func foo() {} |
| 一个返回值 | func foo() error { return fmt.Errorf("...") } |
| 多个返回值 | func foo() (int, string, error) { return 42, "hello", nil } |
多返回值调用
num, str, err := foo()
if err != nil {
fmt.Println("Error:", err)
} else {
fmt.Println("Number:", num)
fmt.Println("String:", str)
}
具名返回值
- 给返回值命名,函数体内直接操作这些变量,最后
return即可:
func calculateCircle(radius float64) (area float64, circumference float64) {
area = 3.14 * radius * radius
circumference = 2 * 3.14 * radius
return // naked return
}
circleArea, circleCircumference := calculateCircle(2.5)
4. 高阶函数
Go 函数是一等公民,可以作为参数传递,也可以作为返回值。
函数作为参数
func performOperation(operation func(int, int) int, a, b int) int {
return operation(a, b)
}
func add(a, b int) int { return a + b }
func subtract(a, b int) int { return a - b }
result := performOperation(add, 10, 5) // Addition Result: 15
result = performOperation(subtract, 10, 5) // Subtraction Result: 5
函数作为返回值
func getOperation(opType string) func(int, int) int {
if opType == "add" { return add }
if opType == "subtract" { return subtract }
return nil
}
addOp := getOperation("add")
subtractOp := getOperation("subtract")
result := addOp(10, 5) // 15
result = subtractOp(10, 5) // 5
5. 匿名函数
语法
func(参数)(返回值){
函数体
}
匿名函数没有函数名,无法像普通函数一样直接调用,只能:
- 定义后立即执行(IIFE)
- 赋值给变量再调用
// 立即执行
func() {
fmt.Println("Hello, World!")
}()
// 赋值给变量
greet := func() {
fmt.Println("Hello, Go!")
}
greet() // Hello, Go!
使用场景选择
- 只需执行一次的简单逻辑 → 立即调用。
- 需要重复调用或传递给其他函数 → 赋值给变量。
6. 闭包
定义:函数 + 引用环境的组合实体。闭包 = 函数 + 引用环境(执行上下文)
闭包函数引用了外部函数的变量,并在外部函数返回后持续持有这个引用。
// 返回一个闭包函数,用于计算累加值
func accumulator() func(int) int {
sum := 0 // sum 是闭包函数引用的变量
return func(x int) int {
sum += x
return sum
}
}
func main() {
acc := accumulator() // 创建一个累加器
fmt.Println(acc(5)) // 5
fmt.Println(acc(10)) // 15 ← sum 被持续更新
fmt.Println(acc(3)) // 18
}
每次调用 acc 时,闭包都更新 sum 变量并返回累加值。
7. defer 语句
定义:defer 将函数调用推迟到包含 defer 语句的函数即将返回前执行,无论函数通过正常 return 还是 panic 返回,defer 都会执行。
执行顺序:LIFO(后进先出)
func main() {
defer printMessage() // 最后执行
defer closeResource() // 倒数第二执行
fmt.Println("Main function body")
}
// 输出:
// Main function body
// Closing resource...
// Printing message...
典型使用场景:文件打开/关闭、锁的获取/释放、资源清理。
defer 参数求值时机:defer 注册时立即对参数求值,函数调用本身延迟。
func main() {
x := 1; y := 2
defer calc("AA", x, calc("A", x, y)) // calc("A",1,2)=3 立即执行,输出 "A 1 2 3"
x = 10
defer calc("BB", x, calc("B", x, y)) // calc("B",10,2)=12 立即执行,输出 "B 10 2 12"
y = 20
}
// 最终输出(LIFO 顺序执行 defer):
// A 1 2 3
// B 10 2 12
// BB 10 12 22
// AA 1 3 4
8. defer 与 return 的执行顺序
当函数同时包含 defer 和 return 时,执行顺序:
- defer 注册:遇到 defer 语句,将调用压栈,不立即执行。
- return 执行:执行 return,将返回结果保存下来(此时返回值已确定)。
- defer 出栈执行:按 LIFO 顺序取出并执行所有 defer 调用。
关键结论:return 执行时返回值就已确定,普通 defer 中对局部变量的修改不影响返回值。
func foo() int {
num := 42
defer fmt.Println("defer 1")
defer func() {
num++ // 修改的是局部变量 num
fmt.Println("defer 2")
}()
fmt.Println("foo")
return num // 返回值在此时确定为 42
}
// 输出:
// foo
// defer 2
// defer 1
// 42 ← 返回值始终是 42,defer 中的 num++ 不影响返回值
| 函数 | defer 引用的变量类型 | 结果 |
|---|---|---|
f1:局部变量 x,非具名返回值 | 局部变量 | return 5,defer x++,返回 5 |
f2:具名返回值 x | 具名返回值 | return 5 → x=5,defer x++ → x=6,返回 6 |
f3:具名返回值 y,defer 操作局部变量 x | 混合 | return x → y=x=5,defer 改局部 x,返回 5 |
f4:defer 接收值拷贝 | 值拷贝 | defer 修改的是拷贝,返回 5 |
9. 内置函数
| 内置函数 | 描述 |
|---|---|
close | 关闭 channel |
len | 返回字符串、数组、slice、map、channel 的长度 |
cap | 返回 slice 容量、channel 缓冲区大小 |
new | 为类型分配内存,返回指针 |
make | 创建 slice、map、channel |
append | 向 slice 末尾追加元素 |
copy | 将源 slice 元素复制到目标 slice |
delete | 从 map 中删除指定键 |
panic | 触发运行时错误 |
recover | 从 panic 中恢复 |
优缺点与局限性
参数值传递
- 适用场景:安全地隔离函数副作用,大多数场景。
- 限制:传递大结构体时有性能开销,需要修改外部状态时需传指针。
- 踩坑:slice/map 是浅拷贝,修改内容影响外部,但 reslice(append 导致扩容)不影响外部变量。
变长参数
- 适用场景:参数数量不固定时(如
fmt.Printf)。 - 限制:变长参数只能是最后一个参数,调用时
slice...解包传入。
闭包
- 适用场景:工厂函数、状态保持、回调。
- 踩坑:循环中使用闭包时,闭包捕获的是变量的引用而非值的拷贝,循环变量可能已变化。需要在循环体内用局部变量隔离。
defer
- 适用场景:资源释放(文件关闭、锁释放)、panic/recover 处理。
- 限制:defer 有微小的性能开销,不适合极端高频调用路径。
- 踩坑①:defer 参数在注册时求值,不是执行时求值。
- 踩坑②:defer 修改局部变量不影响非具名返回值;但 defer 修改具名返回值变量会影响最终返回结果。
具名返回值
- 踩坑:naked return(裸 return)在逻辑复杂的函数中可读性差,慎用。
行动清单
- 动手验证参数传递:分别传
int、[]int、map、*int给函数,打印前后值,体会值拷贝 vs 描述符拷贝的区别。 - 实现高阶函数:写一个
filter([]int, func(int) bool) []int函数,练习函数作为参数。 - 闭包计数器:实现一个
makeCounter()工厂函数,返回(increment func(), get func() int),理解闭包状态共享。 - 循环+闭包陷阱:写一个循环注册 defer 或 goroutine 的例子,验证闭包捕获变量引用的问题,练习用局部变量修复。
- defer 顺序实验:手写包含多个 defer + return 的函数,先预测输出,再运行验证,重点对比具名/非具名返回值的差异。
- 资源管理实践:用 defer 封装一个文件读写操作(
os.Open+defer f.Close()),体会 defer 在资源清理中的实际用法。 - 阅读标准库源码:看
fmt.Fprintf、sort.Slice等函数签名,理解变长参数和高阶函数在生产代码中的使用模式。
方法
一句话摘要
Go 方法的本质是以 receiver 参数作为第一个参数的普通函数;掌握 receiver 的类型选择(T vs *T)、作用域约束与方法集合规则,是正确使用 Go 方法的核心。
核心知识点
1. Go 方法的声明结构
方法由 6 部分组成:func 关键字、receiver、方法名、参数列表、返回值列表、方法体。
与函数的唯一区别:方法多了一个 receiver,它是方法与类型之间的纽带。
func (t *T 或 T) MethodName(参数列表) (返回值列表) {
// 方法体
}
receiver 参数 t 的类型(T 或 *T)中的 T 叫做 基类型:
t的类型是T→ 该方法是类型T的方法t的类型是*T→ 该方法是类型*T的方法
实际示例:
type Person struct {
Name string
Age int
}
func (p Person) SayHello() {
fmt.Printf("Hello, my name is %s. I am %d years old.\n", p.Name, p.Age)
}
func main() {
p := Person{Name: "Forest", Age: 24}
p.SayHello() // 调用方法
}
2. receiver 参数的作用域
receiver 参数、函数/方法参数、返回值变量的作用域,都是函数/方法体对应的显式代码块。
约束 1:receiver 参数名不能与方法参数名或具名返回值变量名冲突,否则编译器报错。
type T struct{}
func (t T) M(t string) { // 编译器报错:duplicate argument t(重复声明参数t)
... ...
}
约束 2:如果方法体中未使用 receiver,可以省略参数名。
type T struct{}
func (T) M(t string) {
... ...
}
约束 3:receiver 基类型本身不能是指针类型或接口类型,否则报错。
type MyInt *int
func (r MyInt) String() string { // 编译器报错:invalid receiver type MyInt(MyInt is a pointer type)
return fmt.Sprintf("%d", *(*int)(r))
}
type MyReader io.Reader
func (r MyReader) Read(p []byte) (int, error) { // 编译器报错:invalid receiver type MyReader(MyReader is an interface type)
return r.Read(p)
}
3. 方法声明与 receiver 的要求
三条硬性规则:
- 方法声明必须与 receiver 基类型声明在同一个包内
- 不能为原生类型(
int、float64、map等)添加方法 - 不能跨越 Go 包为其他包的类型声明新方法
方法的本质公式:
func (t T) M1() <=等价于=> F1(t T)
func (t *T) M2() <=等价于=> F2(t *T)
Go 方法就是一个以 receiver 参数作为第一个参数的普通函数。
4. receiver 参数类型对方法的影响
值类型 receiver(T): 传入的是 T 类型实例的副本,方法体内的修改不影响原始实例。
指针类型 receiver(*T): 传入的是 T 类型实例的地址,方法体内的修改直接反映到原始实例。
自动转换: Go 编译器支持通过值类型变量调用指针接收器方法,会自动取地址:
func (p *Person) UpdateAge(newAge int) {
p.Age = newAge
}
func main() {
p := Person{Name: "Forest", Age: 24}
// 使用值类型变量调用指针接收器方法是合法的
// 编译器会自动转换为 (&p).UpdateAge(30)
p.UpdateAge(30)
fmt.Println("Age after update:", p.Age) // 输出:Age after update: 30
}
5. 选择 receiver 参数类型的原则
选 *T 的场景:
- 需要修改接收者的内部状态时,必须用
*T - receiver 类型体积较大(如
Data [1000000]int),值拷贝开销显著时,用*T更高效:
type BigData struct {
Data [1000000]int
}
func (bd *BigData) ProcessData() {
fmt.Println("process data")
}
func main() {
bd := &BigData{}
bd.ProcessData()
}
选 T 的场景:
- 希望缩窄外部修改类型实例内部状态的”接触面”,尽量少暴露可修改内部状态的方法
- 方法无需修改接收者,基于不可变性和避免副作用的考虑,即使类型较大,使用
T也是合理的 - 需要满足某个接口时,必须用
T作为 receiver(T 类型的方法集合才能直接实现接口)
6. 方法集合与接口实现
定义: 某类型 T 的方法集合与接口类型 I 的方法集合相同,或 T 的方法集合是 I 的超集,则称 T 实现了接口 I。方法集合在 Go 中的主要用途是判断某类型是否实现了某个接口。
示例:
type Speaker interface {
Speak()
}
type Person struct{ Name string }
func (p Person) Speak() {
fmt.Println("Hello, my name is", p.Name)
}
func main() {
p := Person{Name: "Forest"}
var s Speaker = p // Person 实现了 Speaker
s.Speak() // 输出:Hello, my name is Forest
}
结构体方法集合的继承规则: 结构体类型的方法集合包含嵌入字段的方法集合。
方法集合存在交集时的处理:
当结构体通过嵌入多个字段(类型或接口)继承方法,且多个嵌入字段的方法集合存在交集(同名方法),而结构体自身未实现该方法时,会产生编译错误(ambiguous selector),因为编译器无法确定应使用哪个实现。若结构体自身实现了该方法,则优先使用自身实现:
// 接口交集不冲突——同名方法签名相同,C自己实现
type A interface { Method1() }
type B interface { Method1() }
type C struct{}
func (c C) Method1() { fmt.Println("Method1 from C") }
func main() {
var a A
var b B
var c C
a = c
b = c
a.Method1() // Method1 from C
b.Method1() // Method1 from C
}
// 结构体嵌入字段各自实现不同方法——互不干扰
type A struct{}
func (a A) Method1() { fmt.Println("Method1 from A") }
type B struct{}
func (b B) Method2() { fmt.Println("Method2 from B") }
type C struct{ A; B }
func main() {
c := C{}
c.Method1() // Method1 from A
c.Method2() // Method2 from B
}
优缺点与局限性
| 场景 | 适用选择 | 限制/踩坑点 |
|---|---|---|
| 需要修改接收者状态 | *T receiver | 若用 T receiver,修改不会反映到原始实例,是常见 bug |
| 大体积结构体 | *T receiver(通常) | 方法无需修改时用 T 也合理,保持语义清晰 |
| 实现接口 | 看接口方法是否修改接收者 | *T 的方法集合不等于 T 的方法集合,T 类型变量无法赋值给需要 *T 方法的接口变量 |
| 嵌入字段方法冲突 | 自身实现同名方法覆盖 | 若多个嵌入字段有同名方法且自身未覆盖,编译报 ambiguous selector |
| 为原生/外包类型扩展方法 | 不允许 | 必须用 type 定义新类型再扩展,如 type MyInt int |
| receiver 参数名冲突 | — | receiver 参数名必须在方法作用域内唯一,否则编译报错 |
行动清单
- 编码练习: 创建一个
Counter结构体,分别实现Treceiver 的Value()方法和*Treceiver 的Increment()方法,观察对原始实例的影响差异 - 接口验证: 用
var _ InterfaceName = (*YourType)(nil)的编译期断言,验证类型是否正确实现了接口 - 方法集合边界: 实验
T类型变量与*T类型变量分别赋值给接口变量,弄清哪种情况下编译器会报错 - 嵌入冲突实验: 构造两个嵌入字段含同名方法的结构体,亲手触发
ambiguous selector错误,再通过自身实现解决它 - 性能对比: 对含大型数组字段的结构体,分别使用
T和*Treceiver 进行 benchmark,量化拷贝开销 - 延伸阅读: 研究接口类型的方法集合规则(
*T实现接口 vsT实现接口的差异),作为本文的进阶补充
Context
一句话摘要
Go 的 context 包用于在 goroutine 之间和跨 API 边界传递超时、取消信号和请求范围内的值,是 Go 并发编程中协调生命周期的核心工具。
核心知识点
一、Context 接口定义
type Context interface {
Deadline() (deadline time.Time, ok bool) // 截止时间
Done() <-chan struct{} // 取消信号通道
Err() error // 取消原因
Value(key any) any // 键值存取
}
四个核心方法
Deadline(): 返回 Context 截止时间,无截止时间时返回零值 + false。
deadline, ok := ctx.Deadline()
if ok {
// Context 有截止时间
}
Done(): 返回只读通道,Context 被取消时通道关闭。永不取消则返回 nil。
select {
case <-ctx.Done():
// Context 已取消
default:
// Context 尚未取消
}
Err(): 返回取消原因,未取消时返回 nil。
if err := ctx.Err(); err != nil {
// 处理取消错误
}
Value(): 读取 Context 中携带的键值对,不存在时返回 nil。
value := ctx.Value(key)
if value != nil {
// 存在关联的值
}
二、Context 的六种创建方式
context.Background()
根 Context,无值、无取消、无超时,通常作为所有 Context 的起点。
ctx := context.Background()
context.TODO()
用途和 Background() 相同,用于不确定该用哪个 Context 的场景,是一种占位标识。
ctx := context.TODO()
context.WithValue()
创建携带键值对的子 Context,用于传递请求范围内的数据。
// 正确做法:用自定义类型作为 key,避免包间键名冲突
type contextKey string
const userNameKey contextKey = "userName"
ctx := context.WithValue(parentCtx, userNameKey, "用户")
// 读取值
if name, ok := ctx.Value(userNameKey).(string); ok {
fmt.Println("用户名:", name)
}
⚠️ 不要直接用字符串字面量作为 key,会导致不同包之间意外键名冲突。
context.WithCancel()
创建可手动取消的子 Context,调用 cancel 函数后,该 Context 及其所有子孙 Context 均被取消。
ctx, cancelFunc := context.WithCancel(parentCtx)
defer cancelFunc() // 确保退出时释放资源
context.WithCancelCause() + context.Cause()
Go 1.20 新增,在 WithCancel 基础上支持传入取消原因(error)。
ctx, cancelFunc := context.WithCancelCause(parentCtx)
cancelFunc(fmt.Errorf("用户手动取消操作"))
// 获取取消原因
err := context.Cause(ctx)
if err != nil {
fmt.Printf("操作被取消,原因: %v\n", err)
}
context.WithDeadline()
设置具体截止时间点,到达时自动取消。
deadline := time.Now().Add(time.Second * 2)
ctx, cancelFunc := context.WithDeadline(parentCtx, deadline)
defer cancelFunc()
context.WithTimeout()
设置超时时长(底层调用 WithDeadline),到达时自动取消。
ctx, cancelFunc := context.WithTimeout(parentCtx, time.Second*2)
defer cancelFunc()
三、核心使用场景
场景一:传递共享数据(HTTP 中间件)
type key int
const requestIDKey key = iota
func WithRequestId(next http.Handler) http.Handler {
return http.HandlerFunc(func(rw http.ResponseWriter, req *http.Request) {
requestID := req.Header.Get("X-Request-ID")
if requestID == "" {
requestID = generateRequestID()
}
ctx := context.WithValue(req.Context(), requestIDKey, requestID)
req = req.WithContext(ctx)
next.ServeHTTP(rw, req)
})
}
场景二:传递取消信号,终止 goroutine
func main() {
ctx, cancelFunc := context.WithCancel(context.Background())
go Working(ctx)
time.Sleep(3 * time.Second)
fmt.Println("主程序发送取消信号...")
cancelFunc()
time.Sleep(1 * time.Second)
fmt.Println("程序结束")
}
func Working(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("工作协程: 接收到取消信号,下班啦...")
return
default:
fmt.Println("工作协程: 用户正在工作中...")
time.Sleep(500 * time.Millisecond)
}
}
}
场景三:超时控制
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
done := make(chan bool, 1)
go func() {
fmt.Println("开始执行耗时操作...")
time.Sleep(5 * time.Second) // 模拟耗时5秒的操作
done <- true
}()
select {
case <-done:
fmt.Println("操作完成")
case <-ctx.Done():
if ctx.Err() == context.DeadlineExceeded {
fmt.Println("操作已超时 (3秒限制)")
} else {
fmt.Printf("操作被取消: %v\n", ctx.Err())
}
}
}
// 输出:
// 开始执行耗时操作...
// 操作已超时 (3秒限制)
四、使用规则
// ✅ 正确:Context 作为函数第一个参数显式传递
func DoSomething(ctx context.Context, arg Arg) error {
// ... use ctx ...
}
// ❌ 错误:不要把 Context 放进结构体
type MyStruct struct {
ctx context.Context // 禁止
}
// ❌ 错误:不要传递 nil Context
DoSomething(nil, arg)
// ✅ 正确:不确定时用 TODO()
DoSomething(context.TODO(), arg)
四条核心规则:
- Context 必须作为函数第一个参数显式传递,命名为
ctx - 不允许传递
nilContext,不确定时使用context.TODO() - Context 只用于传递请求作用域数据,不用于传递函数可选参数
- WithValue 的 key 必须用自定义类型,不能用内置类型或字符串字面量
优缺点与局限性
| 特性 | 适用场景 | 限制 / 踩坑点 |
|---|---|---|
| WithCancel | 手动控制 goroutine 生命周期 | 必须调用 cancel,否则资源泄漏;建议 defer cancelFunc() |
| WithTimeout | 数据库查询、RPC 调用等超时控制 | goroutine 超时后不会自动终止,需监听 ctx.Done() 主动退出 |
| WithValue | 传递 requestID、用户信息等 | 不能用于替代函数参数;key 类型不当会导致包间冲突 |
| WithCancelCause | 需要区分不同取消原因时 | Go 1.20+ 才支持,需注意版本兼容性 |
| Context 树形传播 | 父 Context 取消自动传播到子孙 | 子 Context 取消不会影响父 Context |
通用踩坑点:
- 忘记调用
cancel()→ goroutine 泄漏、资源无法释放 - 在
select中未处理ctx.Done()→ goroutine 无法被外部取消 - 用
ctx.Err()区分超时(DeadlineExceeded)和主动取消(Canceled)时需注意判断顺序
行动清单
- 实现超时中间件:用
WithTimeout给 HTTP 处理函数加 3 秒超时,验证超时后 goroutine 是否正确退出 - 实现可取消的并发任务:启动多个 goroutine,父 goroutine cancel 后观察所有子 goroutine 是否全部退出
- 验证 WithValue 键冲突:用字符串 key 和自定义类型 key 分别测试,观察跨包时的键覆盖问题
- 使用 WithCancelCause:在取消时传入不同错误,用
context.Cause()获取原因并做分支处理 - 阅读标准库源码:阅读
context.go中cancelCtx、timerCtx的实现,理解 Context 树的内部结构
反射
一句话摘要
Go 反射机制允许程序在运行时动态查询和操作变量的类型与值,核心是 reflect 包提供的 Type 和 Value 两个类型,适用于类型检查、动态访问、方法调用等场景,但有性能开销和访问权限限制。
核心知识点
1. 两个核心类型
reflect 包定义了两个核心抽象:
reflect.Type:表示 Go 中每种类型的元信息(类型名、字段、方法签名等)。reflect.Value:封装了一个具体的值,支持读取和修改。
2. 获取类型和值
reflect.TypeOf() 返回变量的类型信息;reflect.ValueOf() 返回变量的值对象。
var x float64 = 3.4
t := reflect.TypeOf(x)
v := reflect.ValueOf(x)
fmt.Println("Type:", t) // 输出: Type: float64
fmt.Println("Value:", v.Interface()) // 输出: Value: 3.4
v.Interface() 将 reflect.Value 还原为 interface{} 类型,可用于后续类型断言。
3. 修改值
通过反射修改变量,必须满足两个前提条件:传入变量的指针 + 通过 Elem() 解引用后调用 CanSet() 检查可设置性。
var x float64 = 3.4
// 传入指针,获取指针类型的反射对象
v := reflect.ValueOf(&x)
// 解引用指针,得到可设置的反射对象
if v.Elem().CanSet() {
v.Elem().SetFloat(7.1)
}
fmt.Println(x) // 输出: 7.1
SetFloat/SetInt/SetString等方法对应不同基础类型的赋值。- 直接传值(非指针)获取的
Value不可设置,CanSet()返回false。
4. 类型断言
对 interface{} 类型的变量,可通过反射提取 Value 后进行运行时类型断言。
var i interface{} = "hello"
v := reflect.ValueOf(i)
if s, ok := v.Interface().(string); ok {
fmt.Println(s) // 输出: hello
}
与原生类型断言 i.(string) 相比,反射路径更灵活,适合处理类型未知的接口变量。
5. 访问结构体字段
访问结构体字段同样需要传入结构体指针,再通过 Elem() 解引用,然后用 FieldByName() 按字段名获取。
type MyStruct struct {
privateField int
}
s := MyStruct{privateField: 1}
// 传入结构体指针,获取指针类型的反射对象
v := reflect.ValueOf(&s)
// 解引用指针,得到结构体的反射对象
structVal := v.Elem()
// 按名称获取字段
field := structVal.FieldByName("privateField")
fmt.Println("Private Field:", field.Int()) // 输出: Private Field: 1
FieldByName()返回reflect.Value,需调用.Int()/.String()等方法读取具体值。- 字段名区分大小写。
6. 调用方法
通过 MethodByName() 获取方法对象,再用 Call() 传参调用,返回值是 []reflect.Value 切片。
type MyMethods struct{}
func (m *MyMethods) MyMethod() string {
return "Hello, World!"
}
obj := &MyMethods{}
method := reflect.ValueOf(obj).MethodByName("MyMethod")
result := method.Call(nil)
fmt.Println("Method Result:", result[0].Interface())
// 输出: Method Result: Hello, World!
Call(nil)表示无参数调用;有参数时传入[]reflect.Value。result[0].Interface()取第一个返回值并还原为interface{}。
优缺点与局限性
适用场景
- 框架类代码:序列化/反序列化(如 JSON、ORM)、依赖注入、测试工具等需要处理未知类型的场景。
- 运行时类型检查与动态分发。
- 操作接口变量时需要知道底层具体类型。
限制与踩坑点
性能开销:反射操作比直接代码执行慢,高频调用路径(如循环内、热点函数)应避免使用反射。
可访问性限制:私有字段(小写命名)和私有方法仅能在同一个包内通过反射访问。跨包时无法直接访问,即使使用 reflect.Value 的 Unsafe* 系列方法也不建议,会破坏 Go 的封装性。
修改值的前置条件易遗漏:必须传指针 + Elem() 解引用 + CanSet() 验证,缺少任一步骤会 panic 或静默失败。
类型安全丧失:反射绕过了编译期类型检查,运行时错误只能在执行时暴露,调试成本更高。
行动清单
- 动手运行所有代码示例:本地跑通 5 个代码片段,重点观察传指针 vs 传值对
CanSet()结果的影响。 - 对比实验:用
reflect.TypeOf对int、*int、interface{}、struct各传一遍,观察输出差异,建立直觉。 - 阅读标准库实现:读
encoding/json的Marshal/Unmarshal源码,看生产级代码如何用反射处理任意结构体。 - 性能基准测试:写一个 benchmark,对比反射调用方法 vs 直接调用的耗时,量化感知性能开销。
- 进阶方向:学习
reflect.Type的NumField()、Field(i)遍历结构体所有字段的用法,为实现自定义序列化工具打基础。 - 注意边界:练习在跨包场景下尝试访问私有字段,观察 panic 信息,加深对可访问性规则的记忆。
泛型 1.18
一句话摘要
Go 1.18 通过引入类型形参、类型约束、泛型类型等机制实现泛型编程,同时对接口定义从”方法集”重新定义为”类型集”,核心适用场景是为不同类型编写相同逻辑。
核心知识点
1. 基础概念体系
| 概念 | 定义 |
|---|---|
| 类型形参 (Type parameter) | 类型定义或函数中的占位符,如 T |
| 类型实参 (Type argument) | 实际传入的具体类型,如 int |
| 类型约束 (Type constraint) | 限定类型形参可接受的类型范围 |
| 类型形参列表 | 所有类型形参的声明,如 `[T int |
| 实例化 (Instantiation) | 传入类型实参将泛型确定为具体类型的操作 |
| 泛型类型 | 定义中带类型形参的类型 |
2. 泛型类型
定义语法:
type Slice[T int|float32|float64] []T
实例化使用:
var a Slice[int] = []int{1, 2, 3} // 正确
var b Slice[float32] = []float32{1.0} // 正确
var c Slice[string] = []string{"hello"} // ✗ string不在约束中
var x Slice[T] = []int{1, 2, 3} // ✗ 不能直接使用未实例化的泛型类型
多类型形参:
type MyMap[KEY int|string, VALUE float32|float64] map[KEY]VALUE
var a MyMap[string, float64] = map[string]float64{
"jack_score": 9.6,
"bob_score": 8.4,
}
类型形参互相套用:
type WowStruct[T int|float32, S []T] struct {
Data S
MaxValue T
MinValue T
}
var ws WowStruct[int, []int] // 正确
// ✗ 错误:T传入int,S的实参必须是[]int,不能是[]float32
ws := WowStruct[int, []float32]{...}
3. 泛型 Receiver
为泛型类型添加方法:
type MySlice[T int|float32] []T
func (s MySlice[T]) Sum() T {
var sum T
for _, value := range s {
sum += value
}
return sum
}
// 使用(必须先实例化)
var s MySlice[int] = []int{1, 2, 3, 4}
fmt.Println(s.Sum()) // 输出:10
实践案例——泛型队列:
type Queue[T interface{}] struct {
elements []T
}
func (q *Queue[T]) Put(value T) {
q.elements = append(q.elements, value)
}
func (q *Queue[T]) Pop() (T, bool) {
var value T
if len(q.elements) == 0 {
return value, true
}
value = q.elements[0]
q.elements = q.elements[1:]
return value, len(q.elements) == 0
}
// 使用
var q1 Queue[int]
q1.Put(1); q1.Put(2)
q1.Pop() // 1
var q2 Queue[string]
q2.Put("A")
q2.Pop() // "A"
4. 泛型函数
定义与调用:
func Add[T int|float32|float64](a T, b T) T {
return a + b
}
Add[int](1, 2) // 手动传入类型实参
Add[float32](1.0, 2.0)
Add(1, 2) // 编译器自动推导类型实参
5. 接口:从方法集到类型集
定义变更:
| 版本 | 接口定义 |
|---|---|
| Go 1.18 之前 | 接口是一个方法集 |
| Go 1.18 开始 | 接口是一个类型集 |
用接口简化类型约束:
type Int interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
type Uint interface {
~uint | ~uint8 | ~uint16 | ~uint32
}
type Float interface {
~float32 | ~float64
}
type Slice[T Int|Uint|Float] []T
~** 符号:指定底层类型:**
type MyInt int
var s2 Slice[MyInt] // 使用~int后,MyInt底层是int,可以实例化
type MyMyInt MyInt
var s3 Slice[MyMyInt] // MyMyInt底层也是int,也可以
类型集的运算:
// 并集(用 |)
type Uint interface {
~uint | ~uint8 | ~uint16
}
// 交集(多行定义取交集)
type A interface {
AllInt // ~int|~int8|...|~uint...
Uint // ~uint|~uint8|...
}
// A 的类型集 = AllInt ∩ Uint = ~uint|~uint8|~uint16|~uint32|~uint64
// 空集(无意义但能编译)
type Bad interface {
int
float32 // int 和 float32 无交集,类型集为空
}
6. 两种接口类型
基本接口 (Basic interface):只含方法
type MyError interface {
Error() string
}
// 可用于变量定义,也可用于类型约束
var err MyError = fmt.Errorf("hello world")
一般接口 (General interface):含类型(或类型+方法)
type Uint interface {
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64
}
// ✗ 不能用于变量定义
var uintInf Uint // 错误!
// ✓ 只能用于类型约束
type MySlice[T Uint] []T
7. 内置约束关键词
any: interface{} 的别名,代表所有类型
type Slice[T any] []T // 等价于 type Slice[T interface{}] []T
// 批量替换命令
gofmt -w -r 'interface{} -> any' ./...
comparable: 代表所有可用 == 和 != 比较的类型
type MyMap[KEY comparable, VALUE any] map[KEY]VALUE
Ordered(需自定义): 可大小排序的类型,参考官方 constraints 包
type Ordered interface {
Integer | Float | ~string
}
comparable≠ 可排序,comparable只保证==/!=,不保证>/<。
优缺点与局限性
不支持的用法
| 限制 | 说明 |
|---|---|
| 匿名结构体不支持泛型 | `struct[T int |
| 匿名函数不能定义类型形参 | 但可以使用外部已定义的类型形参 |
| 方法不支持泛型 | 只能通过泛型 receiver 间接使用类型形参 |
| 泛型类型不能用类型断言 | value.(int) 和 type switch 对类型形参无效 |
| 一般接口不能定义变量 | 只能作为类型约束 |
接口类型集的限制规则
// ✗ 并集成员不能有相交部分
type _ interface { ~int | MyInt } // MyInt底层是int,与~int相交
// ✗ 并集中不能有类型形参
type MyInf[T ~int] interface { ~float32 | T }
// ✗ 接口不能直接或间接并入自己
type Bad interface { Bad }
// ✗ 带方法的接口不能写入并集
type _ interface { ~int | error } // error是带方法的接口
// ✗ 并集成员 > 1 时不能并入 comparable
type Bad1 interface { []int | comparable }
~ 的使用限制
// ✗ ~后不能是接口
~error
// ✗ ~后不能是非基本类型
type MyInt int
~MyInt // 错误,必须是基本类型如 ~int
泛型 vs 接口+反射
| 维度 | 泛型 | 接口+反射 |
|---|---|---|
| 编译期类型检查 | ✓ | ✗ |
| 使用复杂度 | 中 | 高 |
| 性能 | 好 | 差 |
| 动态类型判断 | 不支持 | 支持 |
在泛型中使用反射等于同时引入两种复杂度,需慎重评估是否真的需要泛型。
行动清单
- 用泛型重写项目中重复的工具函数(如通用
Map、Filter、Contains) - 实现一个泛型栈或链表,练习泛型 receiver 的完整写法
- 执行
gofmt -w -r 'interface{} -> any' ./...升级现有 Go 1.18+ 项目 - 阅读
golang.org/x/exp/constraints源码,理解Ordered、Integer等约束的官方定义方式 - 对比泛型队列与
interface{}+反射队列的性能差异(benchmark) - 整理项目中所有
接口+反射的动态类型处理,评估哪些可以用泛型替代
泛型 1.25
一句话摘要
Go 1.18 引入泛型后持续演进至 Go 1.25,核心结论:网络上大量早期泛型文章已过时,comparable 约束放宽、类型推断增强、泛型类型别名支持等是必须重新认知的关键变化;泛型适用于”多类型相同逻辑”场景,不是接口+反射的替代品。
核心知识点
1. 类型形参与类型实参
类型形参(Type Parameter)是定义时的占位符,类型实参(Type Argument)是实例化时传入的具体类型。语法使用方括号 [] 声明。
// T 是类型形参
func Add[T any](a T, b T) T {
return a + b
}
// int 是类型实参,实例化时替换所有T
result := Add[int](100, 200)
此基础语法自 Go 1.18 保持稳定,是所有泛型代码的基石。
2. 泛型三要素
泛型类型(Generic Type):在类型定义中包含类型形参。
// T 受 int|float32|float64 约束
type Slice[T int|float32|float64] []T
var intSlice Slice[int] = []int{1, 2, 3}
var floatSlice Slice[float32] = []float32{1.0, 2.0, 3.0}
关键概念:类型约束限制可接受的类型集合;实例化用类型实参替换类型形参生成具体类型。
泛型 receiver:为泛型类型定义方法,方法可操作类型形参。
type Container[T any] struct {
items []T
}
// 泛型 receiver:方法可使用类型形参 T
func (c *Container[T]) Push(item T) {
c.items = append(c.items, item)
}
func (c *Container[T]) Get(index int) T {
return c.items[index]
}
重要限制:Go 目前不支持独立的泛型方法,只能通过泛型 receiver 间接实现。
泛型函数(Generic Function):函数直接使用类型形参,创建独立于类型的算法。
func Find[T comparable](slice []T, value T) int {
for i, v := range slice {
if v == value {
return i
}
}
return -1
}
// 类型推断:编译器自动推导 T 为 int
index := Find([]int{1, 2, 3}, 2)
3. 何时用泛型
泛型不是接口+反射的替代品,解决的是另一类问题:如果你经常为不同类型编写完全相同逻辑的代码,泛型是最合适的选择。
典型用例:通用数据结构(栈、队列、链表)、通用算法(排序、过滤、映射)、数学计算函数。
4. 版本演进关键变化
4.1 comparable 约束放宽(Go 1.20+)
Go 1.18 中,comparable 仅包含严格可比较类型(基本类型、结构体等),不包含可能引发 panic 的接口类型。
Go 1.20 起,comparable 被显著放宽,现在包含所有可比较类型,包括接口类型:
// Go 1.20+ 中这是有效的
func ContainsKey[K comparable, V any](m map[K]V, key K) bool {
_, ok := m[key]
return ok
}
// 现在可以使用 any(interface{})作为键类型
var m map[any]string
// 在 Go 1.20 之前,这会导致编译错误
实际影响:基于 comparable 约束的泛型代码(如泛型 Map 操作)更加实用和强大。
4.2 类型推断增强(Go 1.21+)
Go 1.21 减少了需要显式指定类型参数的情况:
func Pair[T any](a, b T) []T {
return []T{a, b}
}
// 以下代码在 Go 1.21+ 中能正确推断,早期版本可能需要明确类型
p := Pair(1, 2) // T 被推断为 int
4.3 泛型类型别名支持(Go 1.24+)
Go 1.24 完全支持泛型类型别名:
type GenericSlice[T any] []T
// 创建泛型类型别名(Go 1.24+)
type Vector[T any] = GenericSlice[T]
var v Vector[int] = []int{1, 2, 3}
提高了代码的可读性和重构能力。
4.4 新增泛型内置函数(Go 1.21+)
// min/max 适用于任何满足 Ordered 约束的类型
x := min(10, 20) // 返回 10
y := max(3.14, 2.71) // 返回 3.14
z := min("apple", "banana") // 返回 "apple"
// clear 清空各种类型的元素
slice := []int{1, 2, 3}
clear(slice) // slice 变为 []int{0, 0, 0}
m := map[string]int{"a": 1}
clear(m) // m 变为空 map
4.5 接口概念演进(Go 1.18,保持稳定)
接口重新定义为类型集(Type Set),分两类:
// 基本接口(Basic Interface):只有方法,可用于变量定义和类型约束
type Reader interface {
Read(p []byte) (n int, err error)
}
// 一般接口(General Interface):包含类型,只能用于类型约束
type Number interface {
~int | ~float64
}
// 泛型接口
type Processor[T any] interface {
Process(input T) T
}
重要区分:基本接口可用于变量定义;一般接口只能用于类型约束,不能用于变量定义。
5. 类型约束设计模式
可重用的约束通过组合构建:
// 数学运算约束
type Numeric interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 |
~float32 | ~float64
}
// 可比较且可排序约束
type Ordered interface {
Numeric | ~string
}
func Sort[T Ordered](slice []T) {
// 排序实现
}
~T 语法表示底层类型为 T 的所有类型(包括自定义类型)。
6. 类型转换限制与解法
泛型函数内部不能直接将类型形参转换为具体类型:
// 错误:无法直接将 T 转换为 int
func Size[T any](value T) int {
// return int(value) // 编译错误
return 0
}
// 解决方案:使用类型断言
func SizeGeneric[T any](value T) int {
switch v := any(value).(type) {
case int:
return v
case string:
return len(v)
default:
return 0
}
}
7. 性能机制:单态化(Monomorphization)
泛型代码在编译时实例化,为每个类型实参生成独立的代码版本:
// 编译后会为 int 和 float64 生成不同的实现
Print[int](10)
Print[float64](3.14)
- 优点:运行时性能接近手动编写的类型特定代码
- 缺点:二进制文件大小可能增加
8. 接口与泛型的结合使用
接口处理行为多态,泛型处理类型多态,二者互补:
type Stringer interface {
String() string
}
// 泛型处理类型多态
func Join[T Stringer](items []T) string {
var result string
for _, item := range items {
result += item.String()
}
return result
}
9. 版本关键演进对比表
| 特性 | Go 1.18(初始版本) | 最新版本(Go 1.25) | 变化影响 |
|---|---|---|---|
comparable 约束 | 严格,不含接口 | 宽松,含所有可比较类型 | 提高实用性 |
| 类型推断 | 基础功能 | 显著增强 | 减少样板代码 |
| 类型别名 | 不支持泛型别名 | 完全支持 | 提高代码组织性 |
| 内置函数 | 有限的泛型支持 | 新增 min / max / clear | 扩展语言能力 |
优缺点与局限性
泛型的适用场景:需要类型安全的多态代码,特别是通用数据结构和算法;多个类型共享完全相同的逻辑时。
不适用场景:当业务逻辑随类型变化时(应用接口);当只有少数几种类型时(直接写具体实现更清晰);过度泛型化会使代码难以理解。
限制条件:
- 不支持独立的泛型方法,只能通过泛型 receiver 间接实现
- 一般接口(含类型的接口)不能用于变量定义,只能作为约束
- 泛型函数内部不能直接进行类型转换,需用类型断言
- 单态化策略会增加二进制体积
踩坑点:
- Go 1.18/1.19 的
comparable约束与 1.20+ 行为不同,升级时需检查 map 键类型相关的泛型代码 ~T(波浪线)和T的区别:~int匹配所有底层类型为int的自定义类型,int只匹配int本身- 测试泛型代码需覆盖不同类型的实例化,不能只测一种类型
行动清单
- 升级版本检查:如果项目还在 Go 1.18/1.19,先确认是否使用了
comparable约束,升级到 1.20+ 后行为有变化,需要验证。 - 练手顺序:先用泛型实现一个通用栈(Stack)或队列,掌握泛型类型+泛型 receiver 的完整写法;再实现
Map/Filter/Reduce函数,掌握泛型函数写法。 - 约束设计练习:参照
Numeric和Ordered约束的写法,为自己项目的领域类型设计一套可复用约束接口库。 - 学习
golang.org/x/exp包:该包包含官方实验性泛型工具(如slices、maps),其中很多已合并进 Go 1.21 标准库,是学习泛型最佳实践的真实参考。 - 关注 Go 1.21 标准库变化:
slices包和maps包已在 Go 1.21 正式引入,min/max/clear内置函数也在此版本加入,直接开始使用这些。 - 迁移旧代码:如果有手写的
interface{}+ 类型断言的通用容器代码,用泛型重写并对比可读性和类型安全性的差异,加深体感。
error
一句话摘要
Go 用显式的多返回值 + error 接口替代异常机制,配套 defer、fmt.Errorf %w、errors.Is/As、errors.Join 等工具,构成一套从基础到高级的完整错误处理体系。
核心知识点
1. error 接口
error 是 Go 内置接口,定义如下:
type error interface {
Error() string
}
任何实现了 Error() string 方法的类型都满足 error 接口,可直接用于错误处理。
2. 返回错误
函数通常返回两个值:(结果, error)。成功时 error 为 nil,失败时携带错误信息。
func Divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("cannot divide by zero")
}
return a / b, nil
}
errors.New("msg")创建最简单的错误值。- 调用方必须检查返回的
error。
3. 检查错误
result, err := Divide(10, 0)
if err != nil {
fmt.Println("Error:", err)
// 记录日志、重试或向上返回
}
- 惯用模式:调用后立即
if err != nil,避免错误被遗漏。
4. defer 进行资源清理
defer 在函数返回前执行,无论成功还是失败都会运行,是资源清理的标准方式。
func ReadFile(filename string) ([]byte, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close() // 无论结果如何,都会关闭文件
// 读取文件内容...
}
defer保证了file.Close()不会因为提前return或 panic 而被跳过。
5. 错误包装与错误链(Go 1.13+)
fmt.Errorf 配合 %w 动词可把原始错误嵌入新错误,形成错误链。
// 包装错误(创建错误链)
func SomeOperation() error {
_, err := Divide(10, 0)
if err != nil {
return fmt.Errorf("operation failed: %w", err)
}
return nil
}
// 用 errors.Is 检查链中是否含特定错误
func HandleError() {
err := SomeOperation()
if errors.Is(err, ErrDivideByZero) {
fmt.Println("检测到除零错误")
}
}
// 用 errors.As 提取链中特定类型的错误
func ExtractError() {
err := SomeOperation()
var divideErr *DivideError
if errors.As(err, ÷Err) {
fmt.Printf("提取到除法错误: %v\n", divideErr)
}
}
| 函数 | 作用 |
|---|---|
fmt.Errorf("...: %w", err) | 包装错误,保留原始错误引用 |
errors.Is(err, target) | 检查错误链中是否含 target |
errors.As(err, &target) | 从错误链中提取指定类型的错误 |
6. 自定义错误类型
当需要携带额外上下文数据时,定义 struct 并实现 Error() 方法。
// 定义自定义错误类型
type DivideError struct {
Dividend int
Divisor int
Message string
}
// 实现 error 接口
func (e *DivideError) Error() string {
return fmt.Sprintf("除错误: %d / %d: %s", e.Dividend, e.Divisor, e.Message)
}
// 使用自定义错误类型
func SafeDivide(a, b int) (int, error) {
if b == 0 {
return 0, &DivideError{
Dividend: a,
Divisor: b,
Message: "除数不能为零",
}
}
return a / b, nil
}
- 自定义类型配合
errors.As可精确匹配并提取字段值。
7. 错误传播
每个函数检查调用结果,并在错误上追加上下文再向上传递,形成调用链。
func ProcessData() error {
err := validateInput()
if err != nil {
return fmt.Errorf("数据验证失败: %w", err)
}
result, err := calculateResult()
if err != nil {
return fmt.Errorf("计算结果失败: %w", err)
}
err = saveResult(result)
if err != nil {
return fmt.Errorf("保存结果失败: %w", err)
}
return nil
}
- 每层只负责处理本层能处理的,不能处理则包装上下文后向上抛。
8. 处理多个错误(Go 1.20+)
errors.Join 将多个错误合并成一个错误值,内部任意一个可被 errors.Is/As 检出。
func ProcessMultipleTasks() error {
var errs []error
if err := task1(); err != nil {
errs = append(errs, fmt.Errorf("任务1失败: %w", err))
}
if err := task2(); err != nil {
errs = append(errs, fmt.Errorf("任务2失败: %w", err))
}
if err := task3(); err != nil {
errs = append(errs, fmt.Errorf("任务3失败: %w", err))
}
if len(errs) > 0 {
return errors.Join(errs...)
}
return nil
}
// 使用示例
func main() {
if err := ProcessMultipleTasks(); err != nil {
fmt.Printf("发生错误: %v\n", err)
if errors.Is(err, ErrTask1Failed) {
fmt.Println("包含任务1错误")
}
}
}
9. 最佳实践
- 始终处理错误:不忽略任何函数返回的
error。 - 提供有意义的错误信息:信息清晰、具体,包含足够上下文。
- 传递时包装:用
fmt.Errorf + %w追加上下文,但不要每层都包。 - 区分错误类型:需差异化处理时用自定义类型或哨兵错误(
var ErrXxx = errors.New(...))。 - 生产环境记日志:用日志系统记录,而非仅打印到控制台。
- 测试错误路径:为错误分支编写单元测试。
优缺点与局限性
优点:
- 显式处理,编译器强制检查,错误不会被静默吞掉。
- 错误链机制(
%w)让根因清晰可追溯。 errors.Join解决并发/批量操作的多错误聚合问题。
局限性与踩坑点:
- 错误检查代码量大,存在大量
if err != nil重复模式。 %w只能包装一层,多次包装会拉长错误消息,调试时需用errors.Unwrap逐层剥离。- 过度包装(每个调用层都包装)导致错误信息冗余,应只在有意义的边界包装。
errors.Is比较的是值相等(哨兵错误)或Is()方法;errors.As比较的是类型匹配,两者不要混淆。- Go 1.13 之前的代码用
github.com/pkg/errors,接触老项目时注意兼容性。
行动清单
- 动手实现一个完整的
DivideError自定义错误类型,用errors.As提取字段值,验证理解。 - 在一个真实项目中,将
fmt.Println(err)替换为带%w包装的错误传播,对比日志质量差异。 - 阅读 Go 标准库
errors包源码(errors.go、wrap.go),了解Is/As/Unwrap的实现逻辑。 - 练习用
errors.Join(Go 1.20+)重构一段并行任务代码,将多个子任务错误聚合后统一返回。 - 了解哨兵错误(
var ErrNotFound = errors.New("not found"))的定义规范,以及何时用哨兵、何时用自定义类型。 - 学习
defer与具名返回值(named return)结合修改错误值的高级用法,了解其应用场景和陷阱。 - 补充阅读:
github.com/pkg/errors的Cause()/Stack()与标准库%w的区别和迁移路径。
panic
一句话摘要
panic 是 Go 处理不可恢复错误的机制,配合 recover 和 defer 使用;核心结论是:**可预见的错误用 error 返回,程序逻辑错误和初始化失败才用 **panic。
核心知识点
1. panic 是什么
Go 内置函数,签名如下:
func panic(v interface{})
触发后:当前 goroutine 立即停止正常执行 → 开始栈展开(stack unwinding)→ 按 LIFO 顺序执行所有已注册的 defer 函数 → 打印 panic 值和堆栈跟踪 → 终止程序(除非被 recover 捕获)。
参数 v 可以是任意类型,通常传字符串或 error。
2. panic 的触发方式
三类来源:
① 显式调用:代码中直接调 panic() 函数。
② 运行时错误(Go runtime 自动触发):
- 数组/切片索引越界
- 除零操作
- 无效内存地址 / 空指针解引用
- 向已关闭的 channel 发送数据
- 类型断言失败(
value.(type)形式)
③ 内置函数错误使用:
- 不正确的
sync.Map使用(如并发写入) - 某些标准库函数在极端情况下触发
3. panic 和 recover
recover() 是 Go 内置函数,只能在 defer 函数内调用,用于捕获并处理 panic,使程序恢复正常执行流程。
func safelyDoSomething() (err error) {
defer func() {
if r := recover(); r != nil {
// 将 panic 转换为 error 返回
err = fmt.Errorf("recovered from panic: %v", r)
}
}()
// 可能触发 panic 的代码
riskyOperation()
return nil
}
三个关键点:
recover()只在 panic 发生后且在defer函数中调用时才有效recover()返回 panic 传递的值- 如果
recover()成功处理了 panic,程序从 panic 发生点之后的代码继续执行(即 defer 之后返回,而不是继续 panic 那行之后)
4. panic 的适用场景
三类场景适合用 panic:
- 程序初始化失败:启动时必需的资源(配置文件、数据库连接)无法获取
- 编程错误(Bug):数组越界、空指针解引用等本不应该发生的情况
- 不可恢复的状态不一致:程序状态严重损坏,无法继续安全执行
5. panic vs 错误返回
| 情况 | 处理方式 | 示例 |
|---|---|---|
| 可预见的错误 | 返回 error | 文件不存在、网络超时 |
| 程序逻辑错误 | panic | 数组越界、类型断言失败 |
| 初始化失败 | panic 或 log.Fatal | 数据库连接失败 |
对比代码:
// 应该返回 error 的情况
func OpenFile(filename string) (*os.File, error) {
if filename == "" {
return nil, errors.New("filename cannot be empty")
}
return os.Open(filename)
}
// 适合使用 panic 的情况
func MustParseConfig(path string) *Config {
config, err := ParseConfig(path)
if err != nil {
// 配置解析失败,程序无法运行
panic(fmt.Sprintf("failed to parse config: %v", err))
}
return config
}
6. panic 的传播机制
当一个 goroutine 发生 panic 时,按以下顺序传播:
- 当前函数停止执行
- 开始执行所有已注册的
defer函数(LIFO 顺序) - 如果某个
defer调用了recover(),则 panic 被捕获,程序恢复正常执行 - 如果没有
recover捕获,goroutine 终止 - 如果是主 goroutine 发生未捕获的 panic,整个程序退出
关键陷阱:panic 不能跨 goroutine 捕获。子 goroutine 发生的 panic 必须在该 goroutine 内部用 recover 处理,无法在父 goroutine 中捕获。
7. 性能考量
panic和recover涉及运行时栈展开,有一定性能开销- 不应将
panic用于常规控制流程 - 在性能敏感的代码路径中应避免频繁触发
panic
8. 标准库中的 panic
Go 标准库会在以下情况触发 panic:
sync包的竞态检测器发现数据竞争时- 某些
reflect操作在类型不匹配时 - 不正确的
close操作(如关闭 nil channel)
⚠️** 勘误**:json.Unmarshal 在解析无效 JSON 时返回错误,而不是触发 panic(原文有误)。
9. 最佳实践示例
示例 1:安全的类型转换
// 安全的类型断言,避免 panic
func safeCastToString(v interface{}) (string, error) {
str, ok := v.(string)
if !ok {
return "", fmt.Errorf("expected string, got %T", v)
}
return str, nil
}
// 使用场景:当确定类型一定正确时可以使用 panic
func mustCastToString(v interface{}) string {
str, ok := v.(string)
if !ok {
panic(fmt.Sprintf("mustCastToString: expected string, got %T", v))
}
return str
}
示例 2:资源初始化
// 初始化数据库连接,失败时 panic
func initDatabase() *sql.DB {
db, err := sql.Open("postgres", "user=test dbname=test")
if err != nil {
panic(fmt.Sprintf("failed to connect to database: %v", err))
}
// 验证连接
if err := db.Ping(); err != nil {
panic(fmt.Sprintf("database ping failed: %v", err))
}
return db
}
func main() {
// 程序启动时初始化关键资源
db := initDatabase()
defer db.Close()
// 程序主逻辑...
}
示例 3:Web 服务器中的 panic 恢复(最重要的工程实践)
// HTTP 中间件:恢复 panic,避免服务器崩溃
func panicRecoveryMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
defer func() {
if r := recover(); r != nil {
// 记录 panic 信息
log.Printf("recovered panic: %v\n%s", r, debug.Stack())
// 返回 500 错误响应
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
}
}()
next.ServeHTTP(w, r)
})
}
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/api/data", func(w http.ResponseWriter, r *http.Request) {
// 这个处理函数可能会 panic
processRequest(w, r)
})
// 应用 panic 恢复中间件
wrappedMux := panicRecoveryMiddleware(mux)
log.Println("Server starting on :8080")
log.Fatal(http.ListenAndServe(":8080", wrappedMux))
}
优缺点与局限性
适用场景:
- 程序启动阶段的必要资源初始化(数据库、配置)
- 检测到程序内部逻辑不变式被违反
- 库/框架边界处,将内部 panic 转换为 error 暴露给调用方
限制与踩坑:
- panic 不能跨 goroutine 传播,子 goroutine 的 panic 必须在自身内部 recover
recover()在defer函数外部调用无效,返回 nil- 滥用 panic 替代 error 返回会让调用方无法优雅处理错误
panic+recover有运行时开销,不能当作普通异常机制使用- 在库代码中对外暴露 panic 是不良实践;应在包边界处用 recover 转换为 error
行动清单
- 动手写 recover 中间件:实现一个 HTTP 中间件,用
recover捕获 handler 中的 panic 并返回 500,同时打印debug.Stack() - 练习 panic 触发场景:写代码主动触发空指针、越界、类型断言失败,观察运行时输出的堆栈信息格式
- 重构项目中的错误处理:检查代码中是否有将
panic当error用的情况,按照”可预见错误 → return error,逻辑 bug → panic”原则重构 - 研究 goroutine 安全:实验验证 panic 不能跨 goroutine 捕获,为每个手动起的 goroutine 加上
defer recover的防御代码 - 阅读标准库源码:查看
sync/map.go和reflect包中 panic 的使用方式,学习标准库的边界处理风格 - 建立 Must 函数命名规范:对返回值必须有效的函数使用
Must前缀(如MustParseConfig),明确告知调用方该函数会 panic
Slice
一句话摘要
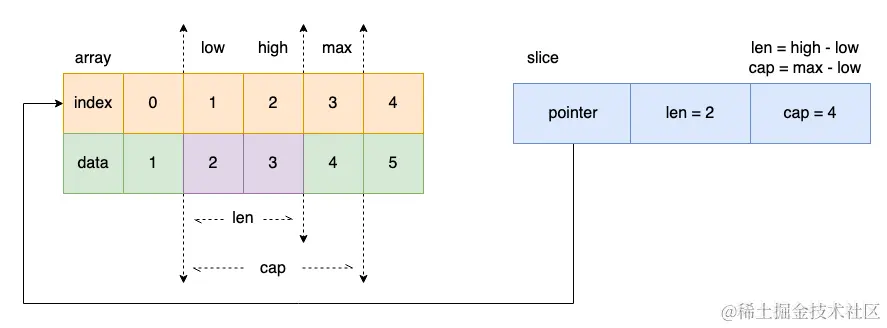
Go slice 是基于数组指针 + len + cap 的结构体,扩容遵循”小切片2倍、大切片平滑过渡到1.25倍”的规则,并经过内存对齐后确定最终容量,函数传参是值传递但共享底层数组,是 Go 中最高频的踩坑源之一。
核心知识点
一、数据结构
type slice struct {
array unsafe.Pointer // 指向底层数组
len int // 当前长度
cap int // 容量
}
二、四种创建方式
数组字面量创建
a := []int{1, 2, 3, 4, 5}
fmt.Println(len(a), cap(a)) // 5, 5
// len == cap == 元素个数
new 创建
c := *new([]int)
fmt.Println(len(c), cap(c)) // 0, 0
切片表达式
a := []int{1, 2, 3, 4, 5}
b := a[1:3:4] // [low:high:max]
fmt.Println(len(b), cap(b), b) // 2, 3, [2 3]
// len = high - low = 3 - 1 = 2
// cap = max - low = 4 - 1 = 3(未指定 max 时:cap = len(a) - low)
// max 不允许大于 len(array)
make 创建
d := make([]int, 5, 5)
fmt.Println(len(d), cap(d)) // 5, 5
// 底层调用 makeslice:
// 1. 计算内存大小 = 元素大小 × 容量(通过 MulUintptr 计算,防止溢出)
// 2. 内存溢出 / 超过 maxAlloc / len<0 / len>cap → panic
// 3. 调用 mallocgc 申请内存
三、扩容规则
触发条件:cap < len + num(append 追加 num 个元素后容量不足)
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap
doublecap := newcap + newcap
// 规则1:newLen > 2倍oldCap → 直接扩到 newLen
if newLen > doublecap {
return newLen
}
const threshold = 256
// 规则2:oldCap < 256 → 直接翻倍
if oldCap < threshold {
return doublecap
}
// 规则3:oldCap >= 256 → 每次扩 (oldCap + 3*256)/4,直到满足 newcap >= newLen
// 效果:从2倍平滑过渡到1.25倍
for {
newcap += (newcap + 3*threshold) >> 2
if uint(newcap) >= uint(newLen) {
break
}
}
// 规则4:newcap 溢出 → 返回 newLen
if newcap <= 0 {
return newLen
}
return newcap
}
⚠️ 网上”小于1024时2倍、大于1024时1.25倍”的说法是旧版本规则,Go 1.18+ 已使用上述平滑过渡方案。
四、内存对齐(真实 cap 与计算 cap 不同的原因)
扩容规则计算出 newcap 后,还会经过 roundupsize 进行内存对齐,最终 cap 会向上取整到内存分配类的边界。
实际案例验证:
a := make([]int, 512, 512)
b := make([]int, 1, 1)
a = append(a, b...)
fmt.Println(len(a), cap(a))
// 输出:513 848
计算过程:
扩容规则计算:
newLen = 513,oldCap = 512
512 >= 256 → 进入平滑过渡
newcap = 512 + (512 + 3×256)>>2 = 512 + 320 = 832
内存对齐:
reqSize = 832 × 8(int字节数) = 6656字节
经过 size_to_class128 和 class_to_size 查表
对齐后 capmem = 6784字节
最终 newcap = 6784 / 8 = 848
五、copy 拷贝规则
func slicecopy(toPtr, fromPtr unsafe.Pointer, toLen, fromLen int, width uintptr) int
// copy 只看 len,不看 cap
// 实际复制数量 = min(len(dst), len(src))
src := []int{1, 2, 3, 4, 5}
dst := make([]int, 3)
n := copy(dst, src)
// n = 3,dst = [1, 2, 3]
六、踩坑集锦
坑1:切片共享底层数组
a := []int{1, 2, 3, 4, 5}
b := a[1:2] // b 和 a 共享底层数组
a[1] = 6
fmt.Println(b) // [6],b 的值跟着变了
坑2:函数参数是值传递,但共享底层数组
// 场景1:直接修改元素 → 影响原切片
func change(b []int) { b[1] = 6 }
// a 被修改
// 场景2:append 触发扩容 → 不影响原切片
func change(b []int) {
b = append(b, 5) // 扩容,b 指向新数组
b[1] = 6 // 修改新数组,不影响 a
}
// a 不被修改
// 场景3:copy 变量后 append,再修改 copy 的变量 → 影响原切片
func change(b []int) {
c := b // c 和 b 共享底层数组
b = append(b, 5) // b 扩容,指向新数组
c[1] = 6 // c 仍指向原数组,影响 a
}
// a[1] 被修改为 6
坑3:传递子切片时 append 覆盖原切片数据
func change(b []int) {
b = append(b, 100) // b 有剩余容量,直接写入底层数组
b[1] = 6
}
func main() {
a := []int{1, 2, 3, 4, 5}
change(a[1:3]) // b = a[1:3],len=2,cap=4
fmt.Println(a) // [1 2 6 100 5]
}
// append(b, 100) 覆盖了 a[3](因为 cap 还有空间)
// b[1]=6 修改了 a[2]
坑4:range 遍历时的行为
// range 遍历次数在循环开始时确定,append 不会导致无限循环
a := []int{1, 2, 3, 4, 5}
for _, v := range a {
a = append(a, v)
}
fmt.Println(a) // [1 2 3 4 5 1 2 3 4 5](只追加了初始5个元素)
// v 的值是每次迭代时从底层数组取的,会受原切片修改影响
a := []int{1, 2, 3, 4, 5}
for i, v := range a {
if i < 4 { a[i+1] += v }
fmt.Println(v)
}
// 输出:1 3 6 10 15(v 反映了 a 被修改后的最新值)
优缺点与局限性
| 特性 | 说明 | 踩坑点 |
|---|---|---|
| 引用语义 | 切片操作高效,无需复制数据 | 子切片修改影响原切片,用 copy 隔离 |
| 值传递 | 函数内修改 slice 头不影响调用方 | 函数内修改元素仍影响原数据,易误判 |
| 扩容后新数组 | append 扩容后返回新切片,不影响原切片 | 忘记接收 append 返回值是最常见的 bug |
| 内存对齐 | 实际 cap 会大于理论计算值 | 不能依赖精确的 cap 值做业务逻辑判断 |
| cap 剩余空间复用 | append 在有 cap 时直接写入底层数组 | 子切片 append 会覆盖原切片后续元素 |
行动清单
- 验证扩容规则:用不同初始 cap(100、256、512、1024)的切片连续 append,打印每次扩容后的 cap,观察平滑过渡规律
- 复现内存对齐差异:
make([]int, 512, 512)追加1个元素后打印 cap,验证 848 的计算过程 - 函数传参实验:复现文中四个 change 函数的场景,在本地逐一运行,确认每种情况下 a 是否被修改
- 子切片陷阱实验:用
a[1:3]传入函数后 append,打印整个 a,验证底层数组被覆盖的现象 - 阅读源码:阅读
runtime/slice.go中的growslice和nextslicecap函数,对照本文扩容规则理解每个分支 - 安全 copy 习惯:梳理项目中所有切片截取操作,确认需要独立副本的地方都使用了
copy而非直接截取
Map 底层
一句话摘要
Go map 基于哈希 + 链地址法实现,通过 hash 值的后 B 位定位 bucket、前 8 位定位 key,配合渐进式扩容和等值扩容保证性能,遍历顺序天然无序且每次随机。
核心知识点
一、基础数据结构
hmap(顶层结构)
type hmap struct {
count int // 元素总数,len(map) 直接返回此值
flags uint8
B uint8 // buckets 数量的对数,bucket 数 = 2^B
noverflow uint16 // overflow bucket 近似数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向当前 bucket 数组,大小为 2^B
oldbuckets unsafe.Pointer // 扩容时指向旧 bucket 数组
nevacuate uintptr // 扩容进度,小于此值的 bucket 已完成迁移
extra *mapextra
}
bmap(bucket 结构)
type bmap struct {
topbits [8]uint8 // 存储每个 key 的 hash 高 8 位
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr // 指向下一个 overflow bucket
}
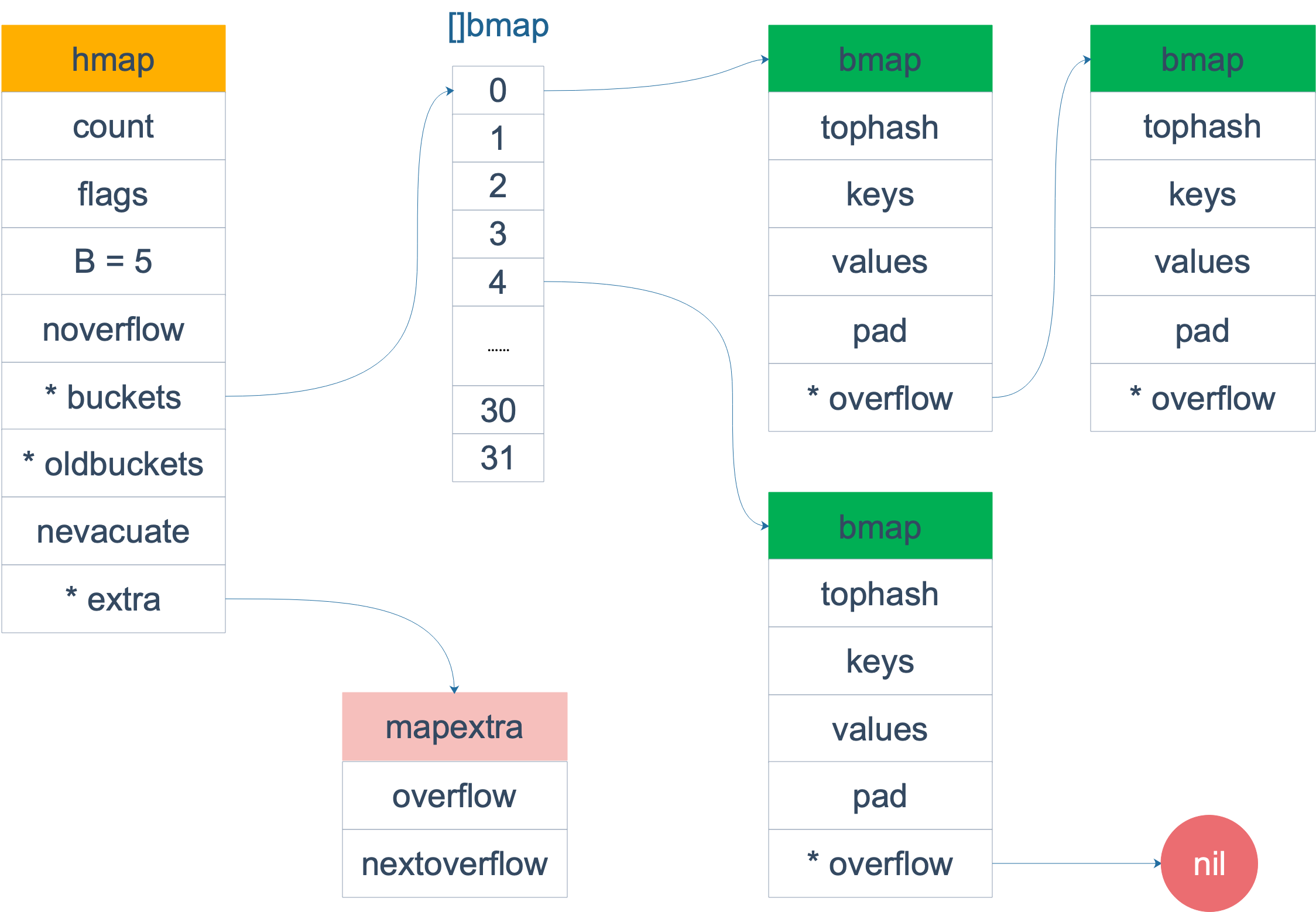
每个 bucket 最多存 8 个 key/value。
key 和 value 分开存储的原因: **避免内存对齐造成的 padding 浪费。**key/value 混存时需要额外 7 字节 padding,分开存储节省内存。

二、Key 定位过程
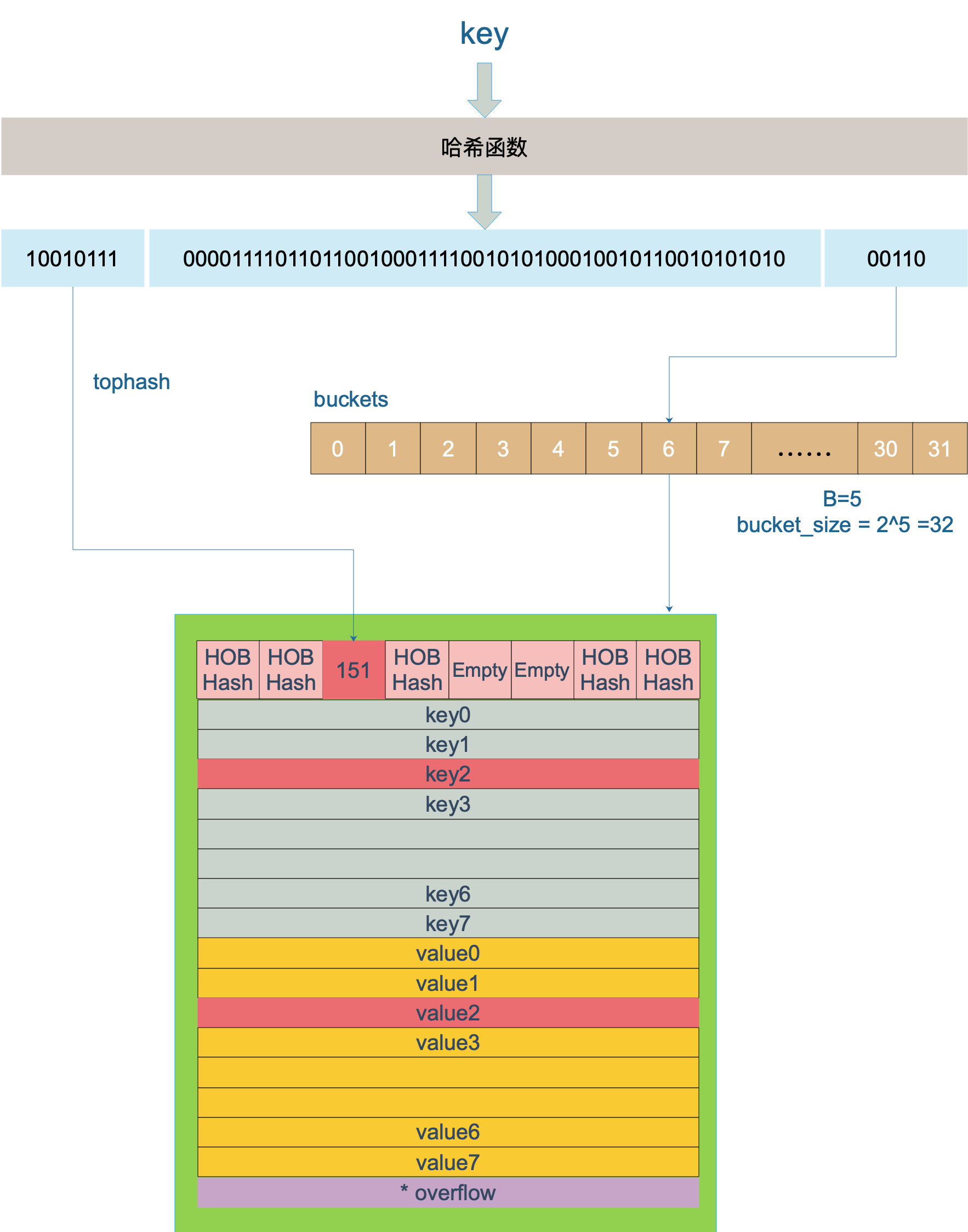
hash(key) → 64位 hash 值
后 B 位 → 确定存储在哪个 bucket
前 8 位(topHash)→ 确定在 bucket 中的位置(0~7)
具体示例(B=5):
hash 值后5位 = 00110 → 十进制 6 → 路由到第6个 bucket
hash 值前8位 = 10010111 → 十进制 151 → 在 tophash 数组中找到位置 3
→ key 在该 bucket 的第3个位置,value 同样在第3个位置
查找流程:
1. hash(key) 取后 B 位 → 定位目标 bucket
2. 在该 bucket 中对比 tophash(前8位)→ 定位 key/value 位置
3. 未找到 → 沿 overflow 指针遍历链式 bucket
4. 所有 overflow 都未找到 → key 不存在
三、四种基本操作
| 操作 | 流程 |
|---|---|
| 新增 | hash → 后B位定位 bucket → topHash 定位空位 → 写入 key/value |
| 查询 | hash → 后B位定位 bucket → 前8位对比 topHash → 找到返回 value |
| 更新 | 同查询定位流程 → 找到后修改 value |
| 删除 | 同查询定位流程 → 找到后将 key/value 置为 nil |
四、扩容机制
触发扩容的两个条件
条件一:装载因子 > 6.5(翻倍扩容)
装载因子 = 元素数量 / bucket 数量
每个 bucket 最多存 8 个 key
装载因子最大值 = 8
装载因子 > 6.5 → 大多数 bucket 快满了 → 触发扩容
扩容方式:bucket 数量翻倍(B+1,bucket 数从 2^B 变为 2^(B+1))
条件二:overflow bucket 过多(等值扩容)
触发场景:
溢出桶数量 >= min(15, B) 时触发
大量插入 → 触发 overflow → 长链表
再大量删除 → bucket 数量不减,但空置率极高
装载因子仍处于 1 < 装载因子 < 6.5
→ overflow bucket 过多,查找效率下降
等值扩容:B 不变,bucket 数量不变
目的:整理稀疏数据,消除过多空 overflow bucket
key 直接搬到相同序号的新 bucket,无需重新计算路由
五、渐进式迁移
翻倍扩容时,旧 bucket 中的 key 需要重新计算路由:
B=5 时:后5位 01001 → 同一个 bucket
B=6 时:后6位变为 101001 或 001001 → 分裂到两个不同 bucket
迁移成本高 → 采用渐进式迁移:
每次插入、修改、删除操作时,顺带迁移 2 个 bucket
直到所有 bucket 迁移完毕
oldbuckets → nil(迁移完成标志)
hmap 扩容时的指针变化:
扩容开始:
旧 bucket → oldbuckets
新 bucket → buckets
迁移完成:
oldbuckets = nil
nevacuate 记录迁移进度(小于此值的 bucket 已完成迁移)
完整流程:
触发扩容
│
├─ 负载因子 > 6.5 ──────► 翻倍扩容(B+1)
│ │
└─ 溢出桶过多 ──────────► 等量扩容(B不变)
│
创建新桶数组,oldbuckets = 旧桶
│
┌──────────────┴──────────────┐
每次 写/删 操作时 读操作时
│ │
growWork() 迁移 1~2 个桶 检查新旧桶,按迁移状态决定去哪读
│
nevacuate 单调推进
│
全部迁移完成 → oldbuckets = nil,扩容结束
六、遍历机制
Go map 遍历天然无序,且每次随机。
原因一: 扩容期间部分 key 在 oldbuckets,部分在 buckets,位置不固定。
原因二(刻意设计): 即使未触发扩容,Go 也会随机选择起始 bucket,防止开发者误认为遍历有序。
随机起点算法:
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
// 从哪个 bucket 开始
it.startBucket = r & (uintptr(1)<<h.B - 1)
// 从 bucket 的哪个 cell 开始
it.offset = uint8(r >> h.B & (bucketCnt - 1))
遍历顺序示例(4个bucket,startBucket=3):
遍历顺序:[3, 0, 1, 2]
→ 先从3号开始,绕回0、1、2,回到3号结束
扩容期间遍历处理:
访问新 bucket 时:
若对应旧 bucket 已迁移 → 直接读新 bucket
若对应旧 bucket 未迁移 → 读旧 bucket 中"应迁移到该新 bucket"的元素
(不读旧 bucket 全部数据,只取计算后归属当前新 bucket 的部分)
优缺点与局限性
| 特性 | 优点 | 限制 / 踩坑点 |
|---|---|---|
| 链地址法 | 冲突处理简单,不影响其他 bucket | 大量删除后 overflow 链变长,查找效率退化 |
| 渐进式扩容 | 扩容平滑,无单次大耗时 | 扩容期间同时维护新旧两个 bucket,内存临时翻倍 |
| 等值扩容 | 消除空洞,不改变 B 值 | 触发条件依赖 overflow bucket 数量,监测有一定延迟 |
| 遍历无序 | 符合 map 语义,避免误用 | 需要有序遍历时必须自行维护 key 切片并排序 |
| key/value 分离存储 | 节省内存对齐 padding | 代码可读性略低于混合存储 |
通用踩坑点:
- 不要依赖 map 遍历顺序,即使数据量固定未触发扩容,顺序也是随机的
- 极端情况下所有 key 后 B 位相同 → map 退化为链表,查找效率 O(n)
- 并发读写 map 会触发
concurrent map read and map writepanic,需用sync.Map或加锁
行动清单
- 验证遍历无序:写一个固定大小 map,多次
for range打印 key 顺序,观察随机性 - 触发扩容观察:用
runtime.ReadMemStats监控插入大量 key 前后的内存变化,观察扩容时机 - 验证 key/value 分离内存收益:用
unsafe.Sizeof对比混合结构体和分离结构体的内存占用差异 - 阅读 runtime/map.go 源码:重点阅读
mapassign、mapaccess1、evacuate函数,对照本文流程理解实现细节 - 对比 Swiss Table:结合 Go 1.24 Swiss Table 笔记,对比新旧两种实现在查找和扩容上的设计差异
Map 实现原理
一句话摘要
Go map 底层是哈希查找表 + 链表法解决冲突,核心结构为 hmap + bmap,理解其内存布局和 key 定位过程是掌握 map 性能特征与扩容机制的基础。
核心知识点
1. map 的两种底层实现方案对比
哈希查找表(Go 的选择)
- 平均查找效率 O(1),最坏 O(N)(哈希函数设计差时退化)
- 遍历结果无序
- 冲突解决:链表法(Go 使用)或开放地址法
自平衡搜索树(AVL / 红黑树)
- 最差查找效率 O(logN),性能下界更好
- 遍历结果有序(按 key 从小到大)
- 实现复杂度高
2. hmap 核心结构体
type hmap struct {
count int // 元素个数,len(map) 直接返回此值
flags uint8
B uint8 // buckets 数组长度的对数,buckets 数量 = 2^B
noverflow uint16 // overflow bucket 近似数
hash0 uint32 // 哈希种子,引入随机性
buckets unsafe.Pointer // 指向 buckets 数组,元素为 0 时为 nil
oldbuckets unsafe.Pointer // 扩容时指向旧 buckets(等量扩容时长度相同,双倍扩容时为新的一半)
nevacuate uintptr // 扩容进度,小于此地址的 buckets 已迁移完成
extra *mapextra
}
关键字段:B 决定桶数量,hash0 保证同一 key 在不同 map 实例中哈希结果不同(防 DoS),oldbuckets 在扩容期间非空。
3. bmap(桶)内存布局
源码中 bmap 只有一个字段,编译器在编译期动态扩充为:
type bmap struct {
topbits [8]uint8 // 每个 key 哈希值的高 8 位(tophash)
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr // 指向溢出桶
}
内存排布关键设计:key 和 value 分开存储(key/key/.../value/value/...),而非交叉存放。
案例:map[int64]int8,若交叉存放每对 kv 需 padding 7 字节;分开存放只在末尾 padding 一次,节省内存。
每个桶最多存 8 个 kv 对,超出后通过 overflow 指针链接溢出桶。
4. GC 优化:bmap 无指针标记
当 key 和 value 都不是指针且 size < 128 字节,bmap 被标记为不含指针,GC 不会扫描整个 hmap。但 overflow 字段是指针,会破坏此设定,因此将 overflow 移动到 hmap.extra 的 mapextra 结构中:
type mapextra struct {
overflow [2]*[]*bmap // [0] 对应 buckets,[1] 对应 oldbuckets 的溢出桶
nextOverflow *bmap // 预分配的空闲溢出桶
}
5. 创建 map:makemap vs makeslice
ageMp := make(map[string]int) // 正常初始化
ageMp := make(map[string]int, 8) // 指定初始容量(hint),减少扩容次数
var ageMp map[string]int // nil map,写入会 panic
底层调用 makemap,返回 *hmap(指针);makeslice 返回 slice 结构体(值类型)。
函数参数传递的差异:
- map 传入函数:值传递的是指针,函数内修改影响原 map
- slice 传入函数:值传递的是结构体副本,函数内 append 等不影响原 slice(除非通过指针传递)
6. 哈希函数选择
启动时在 alginit()(src/runtime/alg.go)中检测 CPU 能力:
- 支持 AES 指令集 → 使用
aes hash(性能更高) - 不支持 → 使用
memhash
map 使用非加密型哈希(目标是查找,优先性能与低碰撞概率,而非安全性)。
每种类型对应的哈希逻辑挂载在 _type.alg(typeAlg)上,包含 hash 和 equal 两个函数指针。string 类型示例:
func strhash(a unsafe.Pointer, h uintptr) uintptr {
x := (*stringStruct)(a)
return memhash(x.str, h, uintptr(x.len))
}
7. key 定位过程(两级索引)
哈希值共 64 bit,分两段使用:
| 哈希位段 | 用途 |
|---|---|
| 低 B 位 | 确定落在哪个 bucket(hash & (2^B - 1),位运算替代取余) |
| 高 8 位(tophash) | 在 bucket 内快速比对,定位具体 slot |
案例(B=5):
哈希值:10010111 | 000011110110110010001111001010100010010110010101010 | 01010
↑低5位=10 → 10号桶
↑高8位=0x97(151) → 在桶内找 tophash==151 的槽位
查找流程(mapaccess1):
- 计算 hash,取低 B 位定位 bucket
- 若
oldbuckets != nil(正在扩容),先检查 oldbucket 是否未迁移,是则在旧桶查找 - 取高 8 位 tophash,遍历桶的 8 个 slot 匹配
- tophash 匹配后再用
alg.equal精确比对 key - 未找到则通过
overflow链继续遍历溢出桶 - 全部未命中,返回零值(不返回 nil)
key/value 地址计算公式:
// key 地址
k := add(unsafe.Pointer(b), dataOffset + i*uintptr(t.keysize))
// value 地址(跳过所有 key 区域)
v := add(unsafe.Pointer(b), dataOffset + bucketCnt*uintptr(t.keysize) + i*uintptr(t.valuesize))
8. tophash 状态机(迁移标记)
tophash 数组除了存高 8 位哈希值,还复用为迁移状态标志:
empty = 0 // 空槽(初始状态)
evacuatedEmpty = 1 // 已迁移的空槽
evacuatedX = 2 // key 已迁移到新桶的前半区
evacuatedY = 3 // key 已迁移到新桶的后半区
minTopHash = 4 // 正常 tophash 的最小值
正常 key 的 tophash 若 < minTopHash,会加上 minTopHash 偏移,避免与状态值冲突。
判断一个桶是否已完成迁移:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash // 即值在 1~3 之间
}
优缺点与局限性
哈希表方案(Go 的选择)
- ✅ 平均 O(1) 查找,性能高
- ✅ 实现相对简单
- ❌ 最坏情况 O(N)(哈希碰撞严重时)
- ❌ 遍历无序,每次 range 顺序不同(Go 故意随机化起始桶来强调这一点)
bmap 设计局限
- 每桶固定 8 槽,溢出靠链表,长链表会退化查询性能
- 扩容期间并发读写会 panic(
hashWritingflag 检测),map 不是并发安全的
nil map 踩坑点
var m map[string]int声明后不初始化,读取返回零值(不 panic);写入直接 panic- 必须用
make初始化后才能写入
函数参数传递踩坑点
- map 作为参数时,函数内修改会影响外部(指针语义)
- slice 作为参数时,函数内
append不会影响外部(值语义),容易误用
行动清单
- 动手验证 nil map 行为:分别对 nil map 做读/写操作,观察输出与 panic 场景。
- 验证 map 参数传递:写一个函数接收 map 并修改,观察调用方的 map 是否同步变化,再与 slice 对比。
- 阅读源码:定位
src/runtime/hashmap.go中makemap、mapaccess1、evacuated函数,对照笔记理解每段注释。 - 绘制 bucket 内存图:以
map[int64]int8为例,手绘 bmap 内存布局,感受 key/value 分区存储的 padding 优势。 - 进一步学习扩容机制:本文末尾涉及
evacuatedX/Y,下一篇重点看 map 的等量扩容(sameSizeGrow)和双倍扩容触发条件(装载因子 > 6.5)。 - 并发安全实践:了解
sync.Map和读写锁sync.RWMutex保护 map 的两种方案,及其适用场景差异。
Map Swiss Table
一句话摘要
Go 1.24 将 map 的底层实现从传统 Hashmap 替换为 Swiss Table,带来查询、插入、删除、迭代的全面性能提升,升级版本即可无感受益。
核心知识点
一、Swiss Table 是什么
Swiss Table 是一种高效的哈希表实现,由 Google 工程师开发,2017 年首次提出,应用于 Google 开源的 Abseil C++ 库。
名字来源:结合紧凑存储和高效查找,类似瑞士军刀般多用途。
二、Swiss Table 五大核心设计
1. 紧凑的存储布局
传统 Hashmap:条目分散存储,缓存未命中率高
Swiss Table:
使用连续内存块(bucket groups)
每个 bucket group 包含 16 个条目
元数据(哈希值高位)存储在紧凑位图结构中
→ 查找时可快速跳过空的或不匹配的条目
2. 高效的查找
查找流程:
通过元数据位图 → 快速定位候选条目位置
避免遍历所有条目
SIMD 技术(单指令多数据):
现代 CPU 一次性检查多个桶
大幅提升查找性能
3. 缓存友好
连续存储布局 + 紧凑元数据 → 减少 CPU 缓存未命中率,充分利用 CPU 缓存层次结构。
4. 减少内存碎片
通过有效内存管理策略,减少因哈希冲突或扩容导致的内存碎片。
5. 渐进式增长
传统 Hashmap:扩容时一次性迁移全部数据 → 性能抖动
Swiss Table:渐进式增长策略 → 扩容平滑,无明显性能波动
三、Go 1.24 Map 性能数据
字节跳动工程师提供的测试报告数据:
| 操作 | 性能变化 | 备注 |
|---|---|---|
| 查询(大 map) | 提升 20%~50% | 查询不存在的元素时提升显著 |
| 查询(小 map) | 下降最多 20% | 元素较少时略有下降 |
| 插入 | 提升 20%~50% | 几乎所有情况 |
| 删除 | 提升 20%~50% | 几乎所有情况 |
| 迭代 | 提升约 10% | |
| 内存使用 | 减少 0%~25% | 复用固定大小 map 不再消耗额外内存 |
四、版本与开关信息
提案发起:2022年(字节跳动工程师发起)
评估周期:2年+
正式发布:Go 1.24(2025年2月)
提案地址:github.com/golang/go/issues/54766
当前状态:实验性特性
关闭 Swiss Table(回退旧实现):
GOEXPERIMENT=noswissmap go build ...
优缺点与局限性
| 维度 | 情况 |
|---|---|
| 大 map 查询 | 显著提升,是 Swiss Table 最强场景 |
| 小 map 查询 | 最多下降 20%,元素少时 Swiss Table 优势不明显 |
| 内存 | 大多数场景减少,固定大小复用 map 收益最大 |
| 稳定性 | 标注为实验性,生产环境需观察 |
| 兼容性 | 无需改代码,升级 Go 版本自动生效 |
踩坑点:
- 小 map 高频查询场景升级前建议先做 benchmark 对比
- 如遇异常可通过
GOEXPERIMENT=noswissmap快速回退验证是否为 Swiss Table 引入的问题
行动清单
- 升级 Go 1.24:将项目 Go 版本升级到 1.24,无需修改代码即可获得 map 性能提升
- Benchmark 对比:对项目中 map 密集操作的模块,用
go test -bench在 1.23 和 1.24 下各跑一次,记录实际提升数据 - 小 map 场景评估:识别项目中元素数量极少(< 5个)且高频查询的 map,重点做性能回归测试
- 对照实验:设置
GOEXPERIMENT=noswissmap关闭 Swiss Table,对比开启前后的性能差异,验证提升效果 - 阅读提案:阅读
github.com/golang/go/issues/54766了解字节工程师的完整测试报告和设计决策
CSP 与并发模型
一句话摘要
Go 将 1978 年 Hoare 提出的 CSP 理论落地为 goroutine + channel 机制,用通信代替共享内存,从语言层面根治了传统多线程并发的复杂性。
核心知识点
1. CSP 是什么
Communicating Sequential Processes,Tony Hoare 1978 年发表于 ACM 的论文。核心主张:并发编程中,进程间的通信(input/output)应被视为第一等公民。
process的定义宽泛:可以是进程、线程,甚至一段代码块- 每个 process 由输入驱动,产生输出供其他 process 消费
- 论文中定义的原语:
!— 向 process 写入(input 命令)?— 从 process 读出(output 命令)->— 守卫命令:左侧表达式为false时,右侧语句不执行
Go 的 channel 操作符 <- 直接借鉴了这套设计。
2. Go 的并发哲学
Do not communicate by sharing memory; instead, share memory by communicating.
传统并发模型与 Go 并发模型的对比:
| 维度 | 传统模型 | Go 模型 |
|---|---|---|
| 并发单元 | Thread(线程) | Goroutine |
| 同步手段 | Mutex / 内存同步访问控制 | Channel |
| 心智负担 | 需关注线程库、线程开销、调度 | 由运行时透明处理 |
3. Goroutine 的定位
- 对标线程,但由 Go runtime 调度,程序员无需关心底层线程开销和调度细节
- 定性:当作免费资源随意使用(Go 并发原则明确如此)
4. Channel 的能力边界
Channel 相比 Mutex 的核心优势在于可组合性:
- 多个子系统的输出 channel 可汇聚到同一个 channel
- 可与
select组合实现多路复用 - 可与
cancel、timeout组合实现超时控制 - Mutex 不具备上述任何组合能力
5. sync 包的定位
Go 内置 sync 包支持传统的内存同步访问控制,适用于局部、明确的共享状态场景。但在大型程序中容易出错,不是首选方案。
优缺点与局限性
Channel 的适用场景
- 跨 goroutine 的数据传递与协调
- 流水线(pipeline)模式
- 超时、取消等控制流
Channel 的局限
- 不适合保护单个共享变量的原子读写(此时
sync/atomic或sync.Mutex更直接) - 滥用 channel 传递锁保护的状态反而引入复杂度
Mutex 的适用场景
- 保护简单的共享计数器、缓存等临界区
- 性能敏感路径,避免 channel 的调度开销
踩坑点
- goroutine 泄漏:channel 无人消费时发送方永久阻塞
- 无缓冲 channel 发送/接收必须同步配对,否则死锁
- 大型系统中混用 Mutex 和 channel 边界不清,维护困难
行动清单
- 读原论文:检索 Tony Hoare 1978 年论文 “Communicating Sequential Processes”,重点阅读
!/?/->原语定义部分,理解 Go channel 的理论根基。 - 动手实现 Pipeline:用 channel 串联 3 个 goroutine(生产者 → 处理 → 消费者),体验”通信共享内存”的编程范式。
- 对比实验:用
sync.Mutex和 channel 分别实现同一个并发计数器,对比代码复杂度与性能(go test -bench)。 - 学习 select 多路复用:掌握
select+ channel 实现超时控制的标准写法:
select {
case result := <-ch:
// 处理结果
case <-time.After(3 * time.Second):
// 超时处理
}
- 阅读 Go 官方建议:精读 Effective Go 并发章节,对照本文的 CSP 原则检验自己的理解。
- 排查 goroutine 泄漏:在实践项目中引入
goleak工具(go.uber.org/goleak),养成检测 goroutine 泄漏的习惯。
锁、WaitGroup、Channel
一句话摘要
Go 并发安全的核心工具有三类:以 sync.Mutex / sync.RWMutex 为代表的共享内存锁机制、用于协程同步的 WaitGroup、以及实现 CSP 模型的 Channel——三者适用不同场景,组合使用可覆盖几乎所有并发需求。
二、核心知识点
1. 互斥锁(sync.Mutex)
概念定义
互斥锁保证同一时刻只有一个 goroutine 进入临界区。获取锁的协程拥有访问权,其余协程阻塞等待。
基本用法
Mutex 实现了 Locker 接口,两个核心方法:
Lock():对临界区上锁,其他协程阻塞等待Unlock():解锁,释放临界区
惯用模式:mu.Lock() 后立即 defer mu.Unlock(),防止忘记解锁。
func main() {
var mu sync.Mutex
var count int
increment := func() {
mu.Lock()
defer mu.Unlock()
count++
fmt.Println("Count:", count)
}
for i := 0; i < 5; i++ {
go increment()
}
time.Sleep(time.Second)
}
内部实现
Mutex 结构体有两个字段:
type Mutex struct {
state int32 // 状态字段
sema uint32 // 信号量
}
state 字段包含 4 种状态含义:
mutexLocked:上锁标志mutexWoken:唤醒标志mutexStarving:正常/饥饿模式标志waiterCount:等待者数量
正常模式 vs 饥饿模式
- 正常模式:等待队列 FIFO,被唤醒的 goroutine 不直接得锁,要与新到的 goroutine 竞争。新来的 goroutine 正在 CPU 上跑,获锁概率更大,减少上下文切换。缺点:被唤醒的 goroutine 可能长期获取不到锁。
- 饥饿模式:等待时间超过 1 微秒时触发。锁直接交给等待队列队首,新请求的 goroutine 不参与竞争,直接排到队尾。当等待队列为空或等待时间低于阈值时,退回正常模式。
2. 读写锁(sync.RWMutex)
概念定义
RWMutex 是读写锁,允许多个读操作并发,但写操作独占。读写互斥,写写互斥,读读不互斥。适用于读多写少场景,解决 Mutex 在读场景下的串行化性能问题。
基本用法
提供 5 个方法:Lock、Unlock、RLock、RUnlock、RLocker
Lock()/Unlock():写操作加锁/解锁,持有写锁时新的读操作阻塞RLock()/RUnlock():读操作加锁/解锁,处于读锁状态时其他协程也能获取读锁RLocker():返回一个Locker接口,Lock()调RLock(),Unlock()调RUnlock()
func main() {
var rw sync.RWMutex
var count int
write := func() {
rw.Lock()
defer rw.Unlock()
count++
fmt.Println("Write:", count)
}
read := func() {
rw.RLock()
defer rw.RUnlock()
fmt.Println("Read:", count)
}
for i := 0; i < 5; i++ { go read() } // Start multiple readers
go write() // Start a single writer
time.Sleep(time.Second)
}
实现原理
RWMutex 通过 readerCount 字段维护读锁数量。写操作时,将 readerCount 减去 2 的 30 次方变成负数,阻塞新的加读锁请求;写锁释放时,再加回 2 的 30 次方,唤醒等待中的读锁操作。
3. 死锁
定义
一组进程相互持有并等待对方资源,所有进程无限期阻塞,无法继续执行。
四个必要条件(Coffman 条件)
- 互斥条件:资源同一时间只能被一个进程持有
- 请求和保持条件:进程持有资源的同时等待其他资源,不释放已有资源
- 不可剥夺条件:资源只能由持有者自己释放
- 循环等待条件:进程集合中形成循环等待链
解决策略
策略一:检测和恢复——系统定期检测死锁,通过回滚操作或强制剥夺资源恢复。
策略二:破坏四个必要条件之一:
- 破坏互斥条件:尽量使用共享资源
- 破坏请求和保持:进程启动时一次性请求所有资源,或请求新资源前释放已持有资源
- 破坏不可剥夺:设计成可强制剥夺资源(如优先级调度)
- 破坏循环等待:对资源排序,要求按序请求
死锁示例代码
// 两个 goroutine 分别持有 mutexA 和 mutexB,并尝试获取对方的锁
go func() {
mutexA.Lock()
fmt.Println("Goroutine 1: Locked mutexA")
mutexB.Lock()
fmt.Println("Goroutine 1: Locked mutexB")
mutexB.Unlock()
mutexA.Unlock()
}()
go func() {
mutexB.Lock()
fmt.Println("Goroutine 2: Locked mutexB")
mutexA.Lock()
fmt.Println("Goroutine 2: Locked mutexA")
mutexA.Unlock()
mutexB.Unlock()
}()
select {}
4. WaitGroup
概念定义
sync.WaitGroup 是 sync 包下的并发原语,用于等待一组 goroutine 全部完成。通过阻塞等待并唤醒来避免轮询等待的 CPU 浪费。
基本用法
三个方法:
Add(delta int):计数器加 deltaDone():计数器减一,等价于Add(-1)Wait():阻塞,直到计数器为 0,唤醒调用者
实现原理
内部维护两个计数器:
v计数器:Add增加,Done减一w计数器:Wait调用时加一
当 v 计数器降为 0 时,唤醒所有 waiter。
示例代码
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // Done() 方法用于减少计数器
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 3; i++ {
wg.Add(1)
go worker(i, &wg)
}
wg.Wait()
fmt.Println("All workers done")
}
5. Channel
概念定义
Channel 是 Go CSP(Communicating Sequential Processes)并发模型的核心实现,goroutine 之间通过 Channel 传递数据而非共享内存。核心理念:“通过通信来实现共享内存,而不是通过共享内存来通信。”
应用场景
- 数据交互:模拟并发 Buffer/Queue,实现生产者-消费者模式
- 数据传递:将数据传给其他 goroutine 处理
- 信号通知:传递 close、data ready 等信号
- 并发编排:通过阻塞等待机制,让 goroutine 按顺序并发或串行执行
- 实现锁功能:利用阻塞等待机制模拟互斥锁
基本用法
Channel 三种类型:
- 只读:
<-chan T - 只写:
chan<- T - 双向:
chan T
Channel 用 make 初始化;未初始化的零值为 nil,对 nil 的 Channel 发送/接收会永久阻塞。
无缓冲 Channel 是同步的(发送方阻塞直到接收方就绪),有缓冲 Channel 是异步的(满时发送阻塞,空时接收阻塞)。
发送操作:chan<-,接收操作:<-chan,接收可返回两个值 (value, ok),ok 为 false 表示 Channel 已关闭且缓冲无数据。
内置函数 close、cap、len 均可操作 Channel;可作为 select 的 case,也可用于 for range。
实现原理——发送(chansend)
发送语句在底层转化为 chansend 函数,执行逻辑:
- Channel 为
nil→ 调用者阻塞 - Channel 已关闭 → panic
recvq有 receiver → 数据直接交给 receiver,不经过 buffer- 无 receiver,buffer 未满 → 数据放入 buffer
- buffer 满 → 发送者 goroutine 加入
sendq,阻塞休眠,等待唤醒
实现原理——接收(chanrecv)
接收语句在底层转化为 chanrecv 函数,执行逻辑:
- Channel 为
nil→ 调用者阻塞 - Channel 已关闭且队列无缓存元素 → 返回
false和零值 sendq有 sender 且 buffer 有数据 → 先从 buffer 取出,再将 sender 的数据放入 buffer- 无 sender,buffer 有数据 → 从 buffer 取一个元素
- 无 sender 且 buffer 无数据 → receiver 加入
recvq,阻塞等待
实现原理——关闭
- 关闭
nilChannel → panic - 关闭已关闭的 Channel → panic
- 正常关闭:清空
recvq和sendq并唤醒
示例代码(生产者-消费者)
func producer(ch chan<- int, count int) {
for i := 0; i < count; i++ {
ch <- i
fmt.Println("Produced:", i)
}
close(ch)
}
func main() {
ch := make(chan int, 5) // 创建一个带缓冲的 channel
go producer(ch, 10) // 启动生产者
consumer(ch) // 启动消费者
}
三、优缺点与局限性
Mutex
| 方面 | 说明 |
|---|---|
| 适用场景 | 简单共享变量保护、秒杀/计数器等写多场景 |
| 不可重入 | Go 的 Mutex 没有记录持有者信息,同一协程二次 Lock() 直接死锁 |
| 递归调用死锁 | 函数持锁时调用自身,尝试再次获锁,导致死锁 |
| Lock/Unlock 不配对 | 未调用 Unlock 导致死锁;对未锁定的 Mutex 调用 Unlock 触发 panic |
| 复制已使用的锁 | sync.Mutex 是含状态的结构体,复制后多个副本共享状态,行为不可预测,应通过指针传递 |
RWMutex
| 方面 | 说明 |
|---|---|
| 适用场景 | 读多写少,读操作远多于写操作时性能优于 Mutex |
| 不可重入 | 同一协程在持锁后再次请求同一锁会阻塞,形成死锁 |
| 隐藏死锁 | 写锁等待读锁释放时,若读锁内部再次尝试获取读锁(其他逻辑),且新读锁又需等待写锁,则形成死锁;需仔细规划读写锁的获取顺序和范围 |
| 复制风险 | 复制已使用的 RWMutex 同样导致意外行为 |
WaitGroup
| 方面 | 说明 |
|---|---|
| 适用场景 | 等待一批 goroutine 全部完成再继续 |
| 计数器负数 panic | Done() 次数多于 Add() 次数时触发 panic |
| 永久阻塞 | v 计数器增加的值大于减少的值(goroutine 启动了但 Done 未被调用),Wait() 永远不返回 |
| 传递方式 | 必须传指针 *sync.WaitGroup,传值会复制计数器状态 |
Channel
| 方面 | 说明 |
|---|---|
| 适用场景 | goroutine 间通信、事件通知、流水线模式 |
| nil Channel | 对 nil Channel 发送/接收永久阻塞,常见于未初始化就使用 |
| 向已关闭 Channel 发送 | panic;应由发送方负责关闭 Channel |
| 重复关闭 | 关闭已关闭的 Channel 触发 panic |
| 无缓冲 Channel 阻塞 | 发送方和接收方必须同时就绪,否则阻塞 |
四、行动清单
- 立即可做
- 用
go run -race对现有并发代码做竞争检测,找出未保护的共享变量 - 在有共享变量的地方刻意练习
Lock()+defer Unlock()组合的写法,形成肌肉记忆 - 写一个小程序,触发不可重入死锁,并用修正版验证解决方案
- 用
- 进阶实践
- 实现一个读多写少的缓存(如 LRU),对比使用 Mutex 和 RWMutex 的性能差距(
go test -bench) - 手写一个生产者-消费者模型:有缓冲 Channel + goroutine 池,理解 Channel 背压机制
- 练习死锁的四条必要条件,逐一尝试破坏每条条件以消除死锁
- 实现一个读多写少的缓存(如 LRU),对比使用 Mutex 和 RWMutex 的性能差距(
- 深入原理
- 阅读 Go 源码:
sync/mutex.go、sync/rwmutex.go、sync/waitgroup.go,对照state字段的位操作加深理解 - 研究 Channel 的
hchan结构体,理解sendq/recvq的sudog链表如何实现阻塞唤醒 - 学习
select+ Channel 的多路复用机制,理解select如何随机选择就绪 case
- 阅读 Go 源码:
- 扩展学习
- 对比
sync.Mutex和sync/atomic的适用边界:原子操作适合单变量无锁读写,复杂临界区仍需 Mutex - 学习
sync.Cond(条件变量),补全 Go sync 包工具箱 - 了解 Go scheduler 的 GMP 模型,理解 goroutine 阻塞时为何不消耗系统线程
- 对比
Channel
一句话摘要
Channel 是 Go 实现 goroutine 间通信与同步的核心原语,通过类型安全的数据管道替代共享内存,解决并发编程中的数据竞争和协调问题。
核心知识点
1. Channel 是什么
Channel 是 Go 的内置数据类型,本质是一条有类型约束的数据管道。它在不同 goroutine 之间传递数据,同时承担同步职责——发送方和接收方在数据交换时会自动对齐节奏。
2. 四个基本特性
类型安全:每个 Channel 只能传递一种固定类型,该类型可以是任意 Go 类型(包括结构体、接口等)。
缓冲模式:分无缓冲和有缓冲两种,缓冲大小决定可暂存的元素数量。
同步语义:发送和接收操作会自动同步对应的 goroutine,实现隐式协调。
可关闭:Channel 可以被关闭,关闭后禁止继续发送,但已有数据可以继续接收。
3. 创建 Channel
// 无缓冲 Channel(同步模式,发送方阻塞直到有人接收)
ch := make(chan int)
// 有缓冲 Channel(异步模式,缓冲区满才阻塞发送)
chBuffered := make(chan int, 10)
4. 发送与接收
统一使用 <- 操作符,方向决定语义:
ch <- 42 // 发送整数 42 到 Channel ch
v := <-ch // 从 Channel ch 接收数据,赋值给变量 v
5. 有缓冲 Channel 的行为细节
缓冲区未满时,发送方不阻塞;缓冲区已满时,第三个发送操作会阻塞,直到有接收方消费数据或缓冲区出现空位。
chBuffered := make(chan int, 2)
chBuffered <- 1 // 存入缓冲区,不阻塞
chBuffered <- 2 // 存入缓冲区,不阻塞
chBuffered <- 3 // 缓冲区已满,此处阻塞,等待接收方
6. 关闭 Channel
close(ch)
关闭后的行为规则:
- 继续向已关闭的 Channel 发送数据 → 触发
panic - 从已关闭的 Channel 接收数据 → 正常工作,直到所有缓存数据被取完,之后返回零值
7. 用 range 迭代 Channel
range 持续从 Channel 读取,直到 Channel 被关闭且数据耗尽后自动退出循环:
for v := range ch {
fmt.Println(v)
}
注意:如果发送方不调用 close(ch),range 会永久阻塞,导致 goroutine 泄漏。
8. 并发场景下的三种典型用法
同步:协调多个 goroutine 的执行顺序(如等待任务完成信号)。
通信:在 goroutine 之间单向或双向传递数据。
并行聚合:多个 goroutine 并发处理,将结果汇集到同一个 Channel 再统一消费。
9. 完整示例:并发计算累加和
func main() {
numbers := []int{1, 2, 3, 4, 5}
ch := make(chan int)
for _, num := range numbers {
go func(n int) {
ch <- n // 每个 goroutine 发送数字到 Channel
}(num)
}
sum := 0
for i := 0; i < len(numbers); i++ {
sum += <-ch // 主 goroutine 从 Channel 接收并累加
}
fmt.Println("Sum:", sum)
}
工作流程:为每个数字启动一个 goroutine 并发发送,主 goroutine 循环接收固定次数后汇总。
优缺点与局限性
无缓冲 Channel 的阻塞陷阱:发送方和接收方必须同时就绪,否则一方一直阻塞。如果在同一个 goroutine 里既发送又接收,必然死锁。
有缓冲 Channel 的误区:缓冲不等于”不需要接收方”,缓冲区满后依然阻塞;将缓冲大小设太大容易掩盖设计缺陷。
close** 的坑**:只有发送方才应该关闭 Channel;由接收方关闭或重复 close 均会 panic。
range** 的前提**:必须配合 close 使用,否则循环永不退出。
示例代码的隐患:上面的并发累加和示例用无缓冲 Channel,在高并发下 goroutine 数量等于数据量,不适合生产环境大规模使用,应配合 worker pool 模式限制并发数。
行动清单
- 动手验证阻塞行为:在本地分别测试无缓冲和有缓冲 Channel,用
go run故意制造死锁,观察错误信息all goroutines are asleep - deadlock!。 - 实现
range+close的生产-消费模型:写一个生产者 goroutine 发送数据,消费者用for v := range ch接收,验证close触发循环退出。 - 改造累加和示例为 Worker Pool:用固定数量(如 3 个)的 goroutine 消费任务 Channel,体会控制并发度的模式。
- 学习
select语句:Channel 的进阶用法,select可以同时监听多个 Channel,实现超时控制(time.After)和非阻塞收发。 - 阅读 Go 并发哲学:深入理解 “Don’t communicate by sharing memory; share memory by communicating” 这一设计理念,对比 mutex 与 Channel 各自适合的场景。
- 了解
sync.WaitGroup配合 Channel:生产实践中,通常用WaitGroup等待所有 goroutine 完成,再关闭 Channel,而不是像示例那样硬编码循环次数。
内存管理
一句话摘要
从操作系统虚拟内存原理出发,逐层拆解 TCMalloc 的三级缓存设计,再映射到 Golang 的 MCache → MCentral → MHeap 内存分层模型,最终解释 Golang 是如何高效管理堆内存的。
核心知识点
1. 为什么需要内存管理
计算机存储速度金字塔(速度从快到慢):
寄存器 → L1/L2/L3 缓存 → 内存(RAM) → SSD → HDD → 网络
关键数据对比:
| 存储介质 | 读写速度 |
|---|---|
| DDR3 内存 | ~10 GB/s |
| DDR4 内存 | ~50 GB/s |
| SSD | ~300 MB/s(约为 DDR4 的 1/200) |
| HDD | ~100 MB/s(约为 DDR4 的 1/500) |
多进程物理内存的两大困局:
- 每个进程必须预占最大内存上限,导致大量内存闲置浪费
- 多进程并发读写同一物理地址,引发冲突
→ 操作系统引入虚拟内存解决上述问题。
2. 虚拟内存与操作系统内存管理
2.1 虚拟内存
- 操作系统为每个进程提供独立的虚拟地址空间(如
0x00000000 ~ 0xFFFFFFFF),进程只能看见虚拟地址。 - OS 内部维护虚拟地址 → 物理地址的映射关系,进程间物理地址互不可见,消除冲突。
- 三个核心能力:
- 最大化物理内存利用率(含”读时共享,写时复制” Copy-on-Write 机制)
- 进程逻辑空间独立
- 物理内存不足时,将磁盘虚拟为内存扩展(Swap),进程对此透明
读时共享,写时复制(COW): 多进程可共享同一物理内存页做读操作;当某进程发起写操作,OS 将该页复制一份,写进程的虚拟地址重新映射到新物理页。
2.2 MMU(内存管理单元)
- MMU 位于 CPU 内部,负责虚拟地址 → 物理地址的翻译。
- 维护一块 TLB(Translation Lookaside Buffer)缓存近期访问的虚拟页 PTE,加速地址翻译,避免每次都查主存页表。
2.3 页(Page)与页表(Page Table)
- Page:OS 管理内存的基本单位,大小为 4KB(可配置)。
- 页表(Page Table):Page 的数组集合,每个元素称为 PTE(Page Table Entry)。
- PTE 结构 = 有效位 + 物理页号(或磁盘地址)
- 有效位 = 1:虚拟页已加载到物理内存(或 TLB-Cache)
- 有效位 = 0:虚拟页未创建,或已创建但未加载进内存
2.4 CPU 访问内存完整流程(14步精要)
- 进程发出内存请求,CPU 生成虚拟地址(= VPN + VPO)
- MMU 先查 TLB 缓存,命中则直接得到 PPN,拼接 VPO 得物理地址,访问物理内存完成
- TLB 未命中 → 查主存页表,得到 PTE
- PTE 有效位 = 1(页命中)→ 获取物理地址,流程结束
- PTE 有效位 = 0(缺页)→ 触发缺页异常 → OS 选择”牺牲页”换出到磁盘 → 将所缺页加载进来 → 更新 PTE → 重新执行访问
关键性能指标:命中率。缺页频繁 → 频繁触发磁盘 I/O → 性能急剧下降(内存抖动)。
2.5 内存局部性
局部性: 程序在运行时倾向于反复访问相邻地址的内存。局部性越好,缓存命中率越高,性能越好。
实验验证代码: 对长度为 10000 的数组进行步长 step 不同的遍历。
// 执行指令
go test -bench=. -count=3 -benchmem loop_test.go
测试结论(step 越大,内存局部性越差):
| step | 耗时(ns/op) |
|---|---|
| 1 | ~2792 |
| 16 |
GPM 调度模型的局部性关联:新建子 Goroutine 优先放在当前 P 的本地队列,而不是其他 P 的队列,正是为了满足内存局部性,提高 CPU Cache 命中率。
3. 手动实现内存池(理解模型用,非生产代码)
3.1 基础数据结构 Buf
type Buf struct {
Capacity uint32 // 缓冲容量(内存上限)
length uint32 // 有效数据长度
head uint32 // 有效数据头部索引
data unsafe.Pointer // 底层内存首地址
Next *Buf // 下一个 Buf(链表)
}
内存布局示意:
[data 基地址] ----[head]---[head+length]----[Capacity]
^有效区域起点 ^有效区域终点
核心操作:
SetBytes(src []byte):将数据拷贝到data+head位置,更新 lengthGetBytes():从data+head位置读取 length 长度数据Pop(len):head 右移 len,length 减少(标记数据已消费)Adjust():将有效数据 memmove 至 data 基地址,head 重置为 0(整理碎片)Clear():仅重置索引,不释放物理内存(由 BufPool 统一管理生命周期)
3.2 内存池 BufPool 设计
BufPool (Map[Capacity -> Buf链表])
├── 4KB → Buf → Buf → Buf → ... (数量多)
├── 8KB → Buf → Buf → ...
├── 16KB → Buf → ...
├── 64KB → Buf
└── 256KB→ Buf (数量少)
单例模式 + sync.Once 保证全局唯一初始化:
var bufPoolInstance *BufPool
var once sync.Once
func MemPool() *BufPool {
once.Do(func() {
bufPoolInstance = &BufPool{}
bufPoolInstance.initPool()
})
return bufPoolInstance
}
Alloc(size):找最接近 size 的 Buf 链表,摘出一个返回;超过EXTRA_MEM_LIMIT限制则拒绝Revert(buf):根据 buf.Capacity 定位链表,Clear() 后插入链表头部
与 TCMalloc 的区别: BufPool 是全局共享的,所有线程竞争同一把锁;TCMalloc 为每个线程独立维护 ThreadCache,减少锁竞争。
4. TCMalloc 核心思想
4.1 三层缓存架构
Thread 申请内存
↓ (无锁)
ThreadCache(每线程独享)
↓ (加锁,小概率)
CentralCache(所有线程共享)
↓ (加锁,更小概率)
PageHeap(全局堆,直接对接虚拟内存)
↓
OS 虚拟内存
4.2 三个基本概念
| 概念 | 定义 |
|---|---|
| Page | TCMalloc 内存单位,默认 8KB |
| Span | 多个连续 Page 组成,是向 OS 申请内存的基本单位;包含起始 Page 编号 Start 和长度 Length,以双向链表组织 |
| Size Class | 小对象内存刻度,如 8B、16B、32B……,按就近向上取整分配 |
4.3 三类对象分配策略
| 对象分类 | 大小范围 | 分配路径 |
|---|---|---|
| 小对象 | (0, 256KB] | ThreadCache → CentralCache → PageHeap |
| 中对象 | (256KB, 1MB] | 直接 PageHeap(小 Span 链表,≤128 Pages) |
| 大对象 | (1MB, +∞) | 直接 PageHeap(Large Span Set,有序集合) |
小对象完整分配链路(关键步骤):
- Thread → ThreadCache 的 FreeList,无锁
- FreeList 空 → 向 CentralCache 加锁申请,CentralCache 一次返回多个 Span 补充 FreeList
- CentralCache 空 → 向 PageHeap 加锁申请 Span,按 SizeClass 拆分后返回
- PageHeap 不足 → syscall 向 OS 申请虚拟内存
PageHeap 内部管理:
- 128 Pages 以内:每个 Page 刻度对应一个 Span 链表
- 128 Pages 以上:以有序集合(类似 C++
std::set)存放
5. Golang 内存管理模型
Golang 内存管理在 TCMalloc 基础上构建,整体架构几乎一一对应,但有若干关键差异。
5.1 对应关系
| TCMalloc | Golang |
|---|---|
| Page (8KB) | Page (8KB),相同 |
| Span | mSpan |
| ThreadCache | MCache(绑定 P,非线程) |
| CentralCache | MCentral |
| PageHeap | MHeap |
5.2 Golang 独有概念
Object: Golang 内存管理的最小分配单元。一个 mSpan 被平均切分成多个 Object。
- 例:Object Size = 8B,所在 Span = 8KB,则 Span 含 1024 个 Object。
Span Class: Golang 在 Size Class 之上额外定义,每个 Size Class 对应 2 个 Span Class:
Span Class = Size Class * 2 + 0 // scan(含指针,需 GC 扫描)
Span Class = Size Class * 2 + 1 // noscan(不含指针,不需 GC 扫描)
66 个 Size Class:(关键字段含义)
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// ......
// 66 32768 32768 1 0 12.50%
bytes/obj:Object 大小(可能略大于申请大小,存在内部碎片)bytes/span:对应 Span 大小objects:Span 内 Object 数量 =bytes/span / bytes/objtail waste:bytes/span % bytes/obj(尾部碎片)max waste:最坏情况浪费比 =(Object Size - 上一级 Object Size - 1 + tail waste) / Span Size
5.3 MCache(对应 ThreadCache)
关键差异:MCache 绑定 P,不绑定线程(Thread)
- 因为 GPM 中真正并发运行的线程数 = GOMAXPROCS = P 的数量
- MCache 数量 = P 的数量,远少于 ThreadCache 随线程数增长的情况
- 访问 MCache 无需加锁
特殊处理:0 字节对象
// 如果 size == 0,直接返回固定地址 zerobase,不走内存分配流程
if size == 0 {
return unsafe.Pointer(&zerobase)
}
验证:[0]int、struct{} 均返回同一地址,Channel 传 struct{} 因此不消耗内存。
5.4 MCentral(对应 CentralCache)
- 访问需加锁
- 每个 Span Class 维护两个 Span 链表(Golang ≥1.16 改为两个集合):
- NonEmpty Span List / Partial Set:有空闲 Object 的 Span
- Empty Span List / Full Set:无空闲 Object 的 Span(或不确定)
- Partial/Full 各有两个 spanSet(
[2]spanSet),区分 GC 已扫描/未扫描
各层内存交换单位:
Goroutine ↔ MCache : Object
MCache ↔ MCentral : Span
MCentral ↔ MHeap : Page
5.5 MHeap(对应 PageHeap)
- 全局唯一,访问加锁
- 内部由多个 HeapArena 组成,每个 HeapArena 大小 = 64MB(Linux 64位)
- 每个 HeapArena 包含 bitmap(服务 GC,标记对象是否存在、是否被 GC 标记)
- ArenaHint 负责寻址 HeapArena,包含 addr(首地址)、down(是否可扩容)、next(下一个 HeapArena)
- 不够时直接向 OS 虚拟内存申请
5.6 三类对象分配流程(Golang 版)
Golang 比 TCMalloc 多一级 Tiny 对象:
| Golang 分类 | 大小范围 | 分配路径 |
|---|---|---|
| Tiny 对象 | (0, 16B),不含指针 | MCache 中专用 16B Tiny 缓冲区 |
| 小对象 | [16B, 32KB] | MCache → MCentral → MHeap |
| 大对象 | (32KB, +∞) | 直接 MHeap |
Tiny 对象为什么需要:
- 若 bool(1B)走正常流程会匹配到 Size Class=1(8B Object),大量 bool 导致 Size Class=1 的 Span 碎片严重,利用率低
- Tiny 缓冲区(16B)从 Size Class=2 的 Span 取一个 16B Object,多个 Tiny 对象共享,按字节对齐排列
- 平均节省约 20% 内存
Tiny 分配条件: 申请 Object < 16B 且不含指针(含指针的必须走 scan Span,让 GC 可达)
大对象分配路径(>32KB):
- 跳过 MCache、MCentral,直接向 MHeap 申请
- MHeap 计算所需 Pages
- 从 HeapArena 取对应 Pages,不足则向 OS 申请
优缺点与局限性
虚拟内存 Swap 扩展磁盘
- 适用:物理内存短暂不足时的兜底方案
- 限制:磁盘读写速度仅为内存的 1/200(DDR4),频繁 Swap 会导致性能灾难性下降
- 踩坑:线上服务若频繁出现 OOM 之前的 Swap 颠簸,往往比 OOM 本身更难察觉
MCache 绑定 P 而非线程
- 优势:P 数量 = GOMAXPROCS(固定),比线程数稳定,节省内存且无锁
- 局限:P 发生抢占/切换时,MCache 中的 Span 可能出现跨 P 归还问题,MCentral 加锁处理
Tiny 对象优化
- 适用:大量 bool、byte、小 string 等无指针微小对象
- 限制:含指针的小对象无法使用 Tiny 缓冲(GC 可达性要求),仍走普通 Size Class 流程
- 踩坑:struct 中加入一个指针字段,会使原本可进 Tiny 缓冲的对象改走 scan Span,内存使用量显著上升
Size Class 内部碎片
- 踩坑:申请 9B 实际分配 16B(Size Class=2),浪费 7B;极端情况 max waste 可达 87.5%(Size Class=1)
- 建议:对内存敏感场景,尽量将频繁分配的小结构体大小对齐到 Size Class 边界(8、16、32、48…字节)
全局锁层级
- MCache:无锁
- MCentral:Span 级加锁
- MHeap:全局加锁
- 踩坑:高并发场景下如果大量 Goroutine 频繁触发超过 32KB 的大对象分配,会产生 MHeap 全局锁竞争
行动清单
- 验证内存局部性:在自己的项目中用
go test -bench对比行优先/列优先遍历二维数组的性能差异,建立直觉。 - 阅读官方 Size Class 表:执行
cat $(go env GOROOT)/src/runtime/sizeclasses.go,结合 max waste 字段,审视项目中高频分配的结构体是否对齐友好。 - 验证 0 字节与 struct{} 地址:
a := struct{}{}
b := struct{}{}
fmt.Println(&a == &b) // true,共享 zerobase
- 用 pprof 采集堆内存 profile:
go tool pprof http://localhost:6060/debug/pprof/heap,观察 alloc_objects 中是否有大量小对象,考虑用 sync.Pool 复用。 - 阅读 Golang Runtime 源码关键文件:
$GOROOT/src/runtime/sizeclasses.go:Size Class 完整定义$GOROOT/src/runtime/mheap.go:MHeap 数据结构$GOROOT/src/runtime/mcache.go:MCache 与 Tiny 分配逻辑
- 思考 GPM 与内存局部性的关系:回答文章中的思考题——G 创建的子 G 优先放入当前 P 的本地队列,核心原因是让父子 G 共享相同 MCache,减少跨 P 的 Span 申请频率,提升 L1/L2 Cache 命中率。
- 手动跑一遍 zmem 内存池代码:理解 Buf 的 Pop+Adjust 生命周期,再与 sync.Pool 的 Get/Put 机制类比,加深对”预分配 + 复用”模式的理解。
逃逸分析
一句话摘要
Go 编译器通过逃逸分析在编译期决定变量分配在栈还是堆上,理解其原理可以指导写出更少 GC 压力、更高性能的代码。
核心知识点
1. 内存管理的两个动作
- 分配:由逃逸分析决定分配到栈还是堆
- 释放:堆内存由 GC 负责,栈内存由编译器自动释放
2. 栈
- 每个 goroutine 独享自己的栈,不共享
- 存储内容:函数参数、局部变量、调用栈帧
- 随函数创建而分配,随函数退出而销毁
- 由编译器全自动管理,开发者无需关心
3. 堆
- 由编译器 + 开发者共同管理分配,GC 负责释放
- Go 开发中需要关心的内存管理 = 堆内存管理
4. 堆 vs 栈 对比
| 维度 | 栈 | 堆 |
|---|---|---|
| 加锁 | 不需要(goroutine 独享) | 有时需要(多线程竞争) |
| 分配性能 | 高(仅 2 条 CPU 指令) | 低(需找空闲块) |
| 释放性能 | 高(自动) | 低(三色标记等 GC 开销) |
| CPU 缓存 | 友好(内存连续) | 较差 |
堆为什么不是一直需要加锁?
Go 借鉴了 TCMalloc 的线程缓存思想,为每个处理器分配了 mcache,从 mcache 分配内存是无锁的。
5. 逃逸分析
定义: 编译期判断变量生命周期是否完全可知,可知则分配到栈,否则”逃逸”到堆。
查看逃逸分析结果的命令:
go build -gcflags '-m -m -l'
四条触发逃逸的原则:
| 原则 | 分配位置 |
|---|---|
| 编译期无法确定参数类型(interface{}) | 堆 |
| 变量在函数外部存在引用 | 堆 |
| 变量占用内存较大 | 堆 |
| 变量在函数外部无引用且内存小 | 栈 |
6. 逃逸的四个典型案例
案例 1:参数是 interface{} 类型
func main() {
a := 666
fmt.Println(a) // 逃逸!Println 参数是 interface{},编译期无法确定类型
}
案例 2:变量在函数外部有引用
func test() *int {
a := 10
return &a // 逃逸!函数退出后栈帧销毁,若 a 在栈上则变成悬挂指针
}
案例 3:变量占用内存较大
// 逃逸 → 分配到堆
a := make([]int, 10000, 10000)
// 不逃逸 → 分配到栈
a := make([]int, 1, 1)
案例 4:变量大小编译期不确定
func test() {
l := 1
a := make([]int, l, l) // 逃逸!l 是变量,编译期无法确定其值
}
优缺点与局限性
栈分配的局限
- 变量生命周期必须在函数内,不能被外部引用
- 不适合存放大对象(触发逃逸阈值即转到堆)
堆分配的代价
- GC 扫描压力增大
- 内存分配需要寻找合适空闲块,性能较差
- 多协程访问时可能需要加锁
传参策略的踩坑点
| 结构体大小 | 推荐方式 | 原因 |
|---|---|---|
| 较小 | 传值(结构体本身) | 栈上拷贝,开销小于堆分配 |
| 较大 | 传指针 | 避免大量值拷贝,节省内存 |
传指针不一定更快——指针会导致变量逃逸到堆,反而增加 GC 压力。
行动清单
- 在现有项目中执行
go build -gcflags '-m -m -l',找出高频逃逸点 - 检查代码中使用
fmt.Println等 interface{} 参数的调试日志,确认是否在热路径上 - 梳理项目中频繁调用的函数,评估传值 vs 传指针的选择是否合理
- 深入学习 TCMalloc 线程缓存思想及 Go 的 mcache/mcentral/mheap 三级内存管理结构
- 结合 GC 三色标记法,理解堆内存释放的完整链路
协程调度器
一句话摘要
Go 调度器通过 GMP 模型(Goroutine + Machine + Processor)将大量 goroutine 映射到少量 OS 线程上执行,结合 work stealing、hand off、抢占等策略,在避免线程频繁创建销毁的同时,充分利用多核 CPU 并行能力,实现高并发。
核心知识点
1. 调度器演进背景
单进程时代:程序串行执行,无并发,CPU 在进程阻塞时空转浪费。
多进程/线程时代:引入调度器解决阻塞问题,但进程/线程本身的创建、切换、销毁代价高昂。每个线程约占 4MB 内存,大量并发下内存爆炸,且 CPU 大量时间耗在调度切换本身。
协程(coroutine)的引入:将线程分为内核态线程(thread)和用户态线程(co-routine)。CPU 只感知内核态线程,协程在用户态完成调度切换,更轻量。
三种协程与线程映射关系:
| 模型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| N:1 | N 个协程绑定 1 个线程 | 切换在用户态,极轻量 | 无法利用多核;一个协程阻塞导致整个线程阻塞 |
| 1:1 | 1 个协程绑定 1 个线程 | 实现简单,可利用多核 | 协程创建/切换开销等于线程,成本高 |
| M:N | M 个协程绑定 N 个线程 | 克服上述两者缺点 | 实现最复杂 |
Go 采用 M:N 模型,用 goroutine 作为用户态协程。
2. 被废弃的老调度器(GM 模型)
结构:所有 goroutine 放在一个全局队列,所有 M(OS 线程)竞争这个队列。
三个核心缺陷:
- 多个 M 操作全局队列需要加锁,锁竞争激烈。
- M 创建新 G 后需要将 G 转移给其他 M 执行,导致局部性差(G’ 与 G 相关联却不在同一 M 运行)。
- 系统调用引发线程阻塞/取消阻塞频繁,系统开销大。
3. GMP 模型核心结构
三个角色:
| 符号 | 全称 | 职责 |
|---|---|---|
| G | Goroutine | 协程,包含执行栈和状态,占用内存极小(初始几 KB,可自动伸缩) |
| M | Machine / OS Thread | 内核线程,真正在 CPU 上执行的实体 |
| P | Processor | 逻辑处理器,持有本地 G 队列(最多 256 个)和运行 G 所需资源;M 必须绑定 P 才能运行 G |
两级队列:
- P 本地队列:最多存 256 个 G,新建的 G 优先进本地队列。
- 全局队列(Global Queue):P 本地队列满时,将本地队列前一半 + 新 G 移入全局队列。
数量配置:
- P 的数量:由环境变量
$GOMAXPROCS或runtime.GOMAXPROCS()决定,决定了真正并行的 goroutine 数上限。 - M 的数量:默认上限 10000(可通过
runtime/debug.SetMaxThreads修改),有 M 阻塞时会自动创建新 M;M 的数量 ≥ P 的数量。
4. 调度器四大策略
① 线程复用 — Work Stealing(工作窃取)
M 本地 P 的队列为空时,不销毁线程,而是从其他 P 的本地队列尾部偷取一半 G 来执行。
② 线程复用 — Hand Off(移交)
M 因 G 执行系统调用阻塞时,M 将绑定的 P 移交给空闲 M(或新建 M),保证 P 不空转。
③ 利用并行
GOMAXPROCS = N 决定最多 N 个线程同时跑在 N 个 CPU 核上。设置为核数/2,则只利用一半核心。
④ 抢占式调度
一个 goroutine 最多连续占用 CPU 10ms,超时后被抢占,防止其他 goroutine 饿死。(区别于传统 coroutine 的协作式让出)
5. go func() 的完整调度流程
go func()创建新 G,优先放入当前 P 的本地队列;队列满则将本地队列前半部分 + 新 G 移至全局队列。- M 持有 P,从 P 本地队列弹出 G 执行(循环机制)。
- P 本地队列为空时,M 先尝试从全局队列取一批 G(取的数量 =
min(全局队列长度/P数量, 本地队列剩余容量/2),至少取 1 个);全局队列也为空时执行 work stealing。 - G 执行系统调用阻塞 → M 与 P 解绑,P 绑定空闲 M(或新建 M)继续跑其他 G;阻塞的 M + G 退出系统调用后尝试重新获取空闲 P,获取失败则 G 进全局队列,M 进休眠池。
- 非阻塞系统调用:M2 记住 P2 并与 P2 解绑,退出系统调用后优先抢回 P2,失败则找空闲 P,仍失败则 G 进全局队列,M2 休眠。
6. 特殊角色 M0 和 G0
M0:程序启动后的主线程(编号 0),存于全局变量 runtime.m0,不在堆上分配。负责执行初始化和启动第一个 G,之后与普通 M 无异。
G0:每个 M 启动时创建的第一个 goroutine,不指向任何用户函数,专门用于协程调度切换(schedule 函数)和系统调用时的栈空间。每个 M 都有自己的 G0;全局 G0 是 M0 的 G0。
7. 程序启动生命周期
1. runtime 创建 m0 和 g0,两者关联
2. 调度器初始化:初始化 m0、栈、GC,创建 GOMAXPROCS 个 P
3. 为 runtime.main 创建 main goroutine,加入 P 的本地队列
4. m0 绑定 P,取出 main goroutine 开始执行
5. G 退出 → M 继续从 P 取下一个 G,循环直到 main.main 退出
6. runtime.main 执行 Defer/Panic 处理,调用 runtime.exit
8. 自旋线程(Spinning Thread)
没有可执行 G 但处于运行状态的 M,持续轮询寻找 G。系统中自旋线程上限为 GOMAXPROCS 个,超出的空闲线程进入休眠,避免 CPU 浪费。保留自旋线程的原因:销毁再重建 M 有延迟,自旋线程能在新 G 创建时立即响应。
9. 可视化调试 GMP 的两种方式
方式一:go tool trace
// trace.go
f, _ := os.Create("trace.out")
trace.Start(f)
defer trace.Stop()
// ... 业务代码 ...
go run trace.go
go tool trace trace.out
# 浏览器打开 http://127.0.0.1:<port>,点击 view trace
方式二:Debug trace(GODEBUG)
GODEBUG=schedtrace=1000 ./your_program
输出字段含义:
SCHED:调度器日志标志0ms:程序启动至此的时间gomaxprocs:P 的数量idleprocs:空闲 P 数;gomaxprocs - idleprocs= 正在执行 Go 代码的 P 数threads:OS 线程(M)总数spinningthreads:自旋 M 数idlethread:空闲 M 数runqueue=N:全局队列中 G 的数量[a b]:每个 P 本地队列中 G 的数量
优缺点与局限性
GMP 的优势
- G 初始栈仅几 KB,支持百万级 goroutine 并发,内存利用率远优于线程模型。
- P 的本地队列减少了全局锁竞争,work stealing 保证了负载均衡。
- hand off 机制使系统调用阻塞不影响其他 G 的执行。
- 抢占式调度(10ms 时间片)避免协程饥饿。
局限性与踩坑点
GOMAXPROCS设置不当(如设为 1)虽然仍能并发,但无法真正并行,会退化为单核运行。- goroutine 泄漏(G 永久阻塞、无法退出)会导致 M 持续创建,逼近 10000 上限,最终 panic。
- 大量 goroutine 都进入系统调用时,M 数量可能激增,OS 线程上下文切换开销反而增大。
- 非阻塞系统调用退出后,G 可能抢不回原 P,被放入全局队列,增加调度延迟。
- work stealing 只偷取 P 本地队列尾部的一半,调试时看到的执行顺序可能与创建顺序不一致(队列中 G 在转移时会被打乱顺序)。
行动清单
- 验证 GOMAXPROCS 效果:写一个 CPU 密集型程序,分别设置
GOMAXPROCS=1和GOMAXPROCS=runtime.NumCPU(),用time命令对比执行时长,直观感受并行效果。 - 实践 go tool trace:在一个启动了多个 goroutine 的程序里加入
trace.Start/Stop,生成trace.out,在浏览器里分析 G/M/P 的生命周期和调度时序。 - 实践 GODEBUG schedtrace:用
GODEBUG=schedtrace=500运行程序,观察runqueue、idleprocs、spinningthreads的变化,熟悉各字段含义。 - 阅读源码:定位
runtime/proc.go中的schedule()、findrunnable()、execute()三个函数,对应本文调度流程的三个核心步骤。 - 理解 G0 的特殊性:在
runtime/proc.go中搜索g0,观察schedule()函数如何在 G0 栈上运行,以及如何切换到用户 G 的栈。 - 后续延伸:观看配套视频(BV19r4y1w7Nx),并阅读系列下一篇文章,深入 GMP 调度的具体场景(系统调用、goroutine 抢占的信号机制等)。
GC
一句话摘要
Go GC 从 STW 全暂停的标记-清除演进到混合写屏障方案,核心目标是在保证对象不被误回收的前提下,将 STW 时间压缩到接近零。
二、核心知识点
1. Mark-and-Sweep(Go < V1.3)
基本流程(全程 STW):
STW 开始 → 标记所有可达对象 → 清除未标记对象 → STW 结束 → 循环
Go V1.3 小优化: 将 STW 提前到标记阶段,Sweep 阶段不再需要 STW(因为待清理对象已是不可达对象,不存在写冲突)。
三大缺陷:
- STW 导致程序卡顿,CPU 完全用于 GC
- 需要扫描整个 heap
- 清除后产生内存碎片
2. 三色并发标记法(Go V1.5)
三种颜色语义:
- 白色:未被扫描,初始状态;GC 结束后白色 = 垃圾
- 灰色:已发现但子节点未扫描完毕
- 黑色:自身及子节点均已扫描,存活对象
标记流程:
① 所有新对象默认白色
② 从根节点(root set)遍历第一层可达对象 → 置灰
③ 遍历灰色对象:将其子节点白色→灰色,自身灰色→黑色
④ 重复③,直到灰色集合为空
⑤ 回收所有白色对象
仍需 STW 的原因: 并发场景下对象引用关系随时变化,不加 STW 会产生对象丢失(误杀)。
3. 无 STW 三色标记的致命问题
对象丢失的两个必要条件(同时满足才会触发):
- 条件 1:一个白色对象被黑色对象引用(白色挂在黑色下游)
- 条件 2:原来保护该白色对象的灰色对象切断了与它的引用关系
经典误杀场景:
初始:黑色对象4,灰色对象2 → 白色对象3(通过指针p)
并发修改:
对象4 新建指针 q → 对象3 // 白色被黑色引用
对象2 删除指针 p // 灰色失去对白色的保护
结果:对象3 既挂在黑色对象4下,又失去灰色保护
→ 三色标记结束后对象3被当作垃圾回收 → 悬空指针 / 数据丢失
4. 屏障机制(Barrier)
屏障本质是写操作的钩子函数,在对象引用关系发生变化时触发,维持两种不变式之一。
强三色不变式
不允许黑色对象直接引用白色对象的指针。
弱三色不变式
黑色对象可以引用白色对象,但该白色对象的上游链路上必须存在灰色对象保护它。
4.1 插入屏障(Insertion Barrier,V1.5)
规则: A 引用 B 时,将 B 标记为灰色。
满足: 强三色不变式**(新引用的白色对象立即变灰,黑色永远不直接指向白色)。**
伪代码:
writePointer(slot, ptr):
shade(ptr) // 将新引用对象置灰
*slot = ptr
关键限制:插入屏障不作用于栈空间。
**原因:**栈上函数调用频繁,对象生命周期短,加屏障开销太高。
代价: 全部堆扫描结束后,栈上可能仍有白色对象被引用(如对象9)。
→ 必须对栈重新进行一次三色扫描(需 STW),耗时约 10~100ms。
4.2 删除屏障(Deletion Barrier,V1.5)
规则: 被删除引用的对象,若自身为灰色或白色,则标记为灰色。
满足: 弱三色不变式(被断开引用的对象得以在本轮 GC 中存活)。
伪代码:
writePointer(slot, ptr):
shade(*slot) // 将被删除引用的旧对象置灰
*slot = ptr
代价: 回收精度低。一个对象即使失去最后一个引用指针,本轮 GC 也不会被回收,要等下一轮 GC 才能清理。GC 开始时需要 STW 扫描堆栈记录初始快照。
5. 混合写屏障(Hybrid Write Barrier,Go V1.8)
结合插入屏障与删除屏障优点,彻底消除对栈的 re-scan STW。
四条规则:
1. GC 开始时,STW 扫描所有栈上对象,全部标记为黑色(只做这一次,后续无需 re-scan STW)
2. GC 期间,栈上新创建的对象,直接标记为黑色
3. 堆上被删除引用的对象,标记为灰色(删除屏障)
4. 堆上被新增引用的对象,标记为灰色(插入屏障)
满足: 变形的弱三色不变式。
伪代码:
writePointer(slot, ptr):
shade(*slot) // 旧引用对象置灰(删除屏障)
if current stack is grey:
shade(ptr) // 新引用对象置灰(插入屏障)
*slot = ptr
屏障技术仅作用于堆空间,栈空间不触发屏障(保证栈运行效率)。
四类核心场景:
| 场景 | 操作描述 | 结果 |
|---|---|---|
| 1 | 堆对象删除引用某白色对象,该对象成为栈对象的下游 | 被删除的堆对象置灰,对象安全 |
| 2 | 栈对象删除引用,被引用对象转移至另一个栈对象 | 栈对象本身已是黑色,新下游也安全 |
| 3 | 堆对象删除引用,被引用对象成为另一个堆对象的下游 | 旧引用置灰 + 新引用置灰,对象安全 |
| 4 | 栈对象删除引用,被引用对象成为另一个堆对象的下游 | 新引用对象置灰,对象安全 |
三、各版本对比与局限性
| 版本 | 方案 | STW 情况 | 效率 |
|---|---|---|---|
| < V1.3 | 普通标记-清除 | 整个 GC 过程全程 STW | 极低 |
| V1.3 | 标记-清除(Sweep 移出 STW) | 标记阶段 STW | 低 |
| V1.5 | 三色标记 + 插入/删除屏障 | 堆写屏障;栈扫描结束后需 re-scan STW(10~100ms) | 普通 |
| V1.8 | 三色标记 + 混合写屏障 | 仅 GC 开始时并发扫描各 goroutine 栈(无 STW);无 re-scan | 较高 |
踩坑点与限制:
- 插入屏障不覆盖栈,导致栈上必须 re-scan,STW 时间不可控(10~100ms)
- 删除屏障精度低,对象最快也只能在下一轮 GC 被回收,内存释放滞后
- 混合写屏障只在GC 触发期间生效,非 GC 期间无屏障开销
- 混合写屏障对栈无屏障保护,依赖 GC 开始时将栈全黑来保证安全,栈上对象生命周期内不会被误回收
四、行动清单
- 动手画状态机:用纸或白板手绘三色标记的五步流程,重点演练”对象丢失”的触发路径,确认两个必要条件缺一不可。
- 对比阅读 Go runtime 源码:
runtime/mgc.go:GC 主流程与状态机runtime/mbarrier.go:混合写屏障的具体实现(writebarrierptr)
- 复现 GC 行为:在本地用
GODEBUG=gccheckmark=1 go run main.go开启 GC 一致性检查,观察 GC 日志。 - 深入 STW 耗时分析:用
go tool trace捕获 GC 事件,观察STW (sweep termination)和STW (mark termination)的耗时分布。 - 横向对比学习:对比 Java G1/ZGC 的 Remembered Set + SATB(Snapshot-at-the-beginning)方案,理解删除屏障在不同 runtime 中的变体。
- 学习路径推荐:
- 先看配套视频:
https://www.bilibili.com/video/BV1wz4y1y7Kd - 再读《Go 程序员面试笔试宝典》GC 章节
- 最后跟读 Go 官方博客《Getting to Go: The Journey of Go’s Garbage Collector》
- 先看配套视频:
协程泄漏
一句话摘要
Goroutine 泄漏是指无用但未被回收的 goroutine 持续占用内存,核心解法是:用 context 管控生命周期、为 channel 操作设置超时、保证锁按统一顺序获取、用 WaitGroup 等待协程正常退出。
核心知识点
1. 什么是 Goroutine 泄漏
已无实际用途(逻辑上已结束或无法到达执行路径)但未被 GC 回收的 goroutine。随程序运行时间累积,最终导致内存耗尽或性能下降。
2. 泄漏的五大原因
① 无退出条件的长时间运行
goroutine 执行无限循环或长任务时,没有设置任何退出路径,永远存活。
② Channel 操作阻塞
- 发送阻塞:goroutine 向无缓冲 channel 发送数据,但始终没有接收方,发送者永久挂起。
- 接收阻塞:goroutine 等待从 channel 读数据,但发送方已退出,channel 不再有数据,接收者永久挂起。
③ 阻塞的系统调用
文件 I/O、网络请求等操作未设置超时,外部条件长期不满足时,goroutine 永久阻塞。
④ 锁未释放
goroutine 等待 sync.Mutex 等同步原语,若持锁方因 bug 未调用 Unlock(),等待方永久阻塞。
⑤ 循环等待(死锁)
多个 goroutine 互相等待对方持有的锁,形成环形依赖,全部无法推进。
3. 解决方法
方法一:用 context 控制 goroutine 生命周期
通过 context.WithTimeout / context.WithCancel 向 goroutine 传递退出信号,goroutine 内部用 select 监听 ctx.Done()。
func doSomething(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("goroutine exiting")
return // 正确退出
default:
fmt.Println("working...")
time.Sleep(1 * time.Second)
}
}
}
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
go doSomething(ctx)
time.Sleep(5 * time.Second)
}
WithTimeout在 3 秒后自动触发ctx.Done()defer cancel()保证资源释放,即使提前返回也不泄漏
方法二:为 Channel 操作设置超时
用 time.After 配合 select,避免 channel 操作永久阻塞。
发送超时:
select {
case ch <- 1:
fmt.Println("sent value")
case <-time.After(1 * time.Second):
fmt.Println("timeout on send")
}
接收超时:
select {
case v := <-ch:
fmt.Println("received value", v)
case <-time.After(1 * time.Second):
fmt.Println("timeout on receive")
}
方法三:按统一顺序获取锁,避免死锁
多个 goroutine 必须以相同顺序获取多把锁,打破环形依赖。
以下是会死锁的反例(goroutine 1 先锁 A 再锁 B,goroutine 2 先锁 B 再锁 A):
// goroutine 1
lockA.Lock() → lockB.Lock()
// goroutine 2(顺序相反,产生死锁)
lockB.Lock() → lockA.Lock()
修复方式:强制两个 goroutine 都按 lockA → lockB 的顺序获取锁。
方法四:用 sync.WaitGroup 等待所有协程正常退出
WaitGroup 通过计数确保主流程在所有 goroutine 完成后才继续,防止程序提前退出”遗弃”仍在运行的 goroutine。
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // 退出时计数 -1
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1) // 计数 +1
go worker(i, &wg)
}
wg.Wait() // 阻塞直到计数归零
fmt.Println("All workers done")
}
优缺点与局限性
| 方法 | 适用场景 | 限制 / 踩坑点 |
|---|---|---|
context 超时/取消 | 有明确生命周期的后台任务、请求链路 | goroutine 内部必须主动检查 ctx.Done(),否则无效;cancel() 必须调用否则泄漏 context 本身 |
time.After 超时 | 单次 channel 收发操作 | time.After 每次调用都新建 timer,高频场景应用 time.NewTimer + Reset 代替,避免 timer 自身泄漏 |
| 统一锁顺序 | 多锁并发场景 | 需要在设计阶段就规定全局锁顺序,运行时无法自动检测顺序错误;复杂系统中难以全局维护 |
sync.WaitGroup | 批量并发任务、等待所有子任务结束 | 不能解决内部存在无限循环或资源死锁的 goroutine 泄漏;wg.Add() 必须在 go 语句前调用,否则 Wait() 可能提前返回 |
行动清单
- 排查现有代码:检查所有
go func()启动的 goroutine,确认每一个都有明确的退出路径(return、ctx.Done()、channel 关闭)。 - 实践
context模式:为所有后台 goroutine 传入context.Context,用select + ctx.Done()替代裸循环。 - 替换裸 channel 操作:将无超时保护的
ch <- val和v := <-ch统一改为select + time.After形式。 - 使用
goleak工具检测泄漏:在单元测试中引入go.uber.org/goleak,自动检测测试结束后残留的 goroutine。 - 监控线上 goroutine 数量:通过
runtime.NumGoroutine()暴露 metrics,设置告警阈值,及时发现泄漏趋势。 - 死锁专项演练:手写一个死锁场景并用
go tool pprof或SIGQUIT触发 goroutine dump 分析,熟悉排查流程。